


Technologies for Assisting Manual Order Picking |
From conventional pick-by systems to AI-driven manual picking assistance
| Journal | Industry 4.0 Science |
| Issue | Volume 41, Edition 4, Pages 6-19 |
| Open Access | https://doi.org/10.30844/I4SE.25.4.6 |
| Bibliography | Share | Cite | Download |
Abstract
Keywords
Article
As automation advances across Industry 4.0, many industrial processes are being redefined. Still, order picking continues to rely heavily on human workers. Why does this task remain so human-centric? And how can emerging technologies enhance, not replace, their role? This article explores these questions and outlines new directions that combine perception and language-based technologies.
Order picking remains one of the most cost-intensive and error-prone processes in warehouse and assembly logistics. Manual approaches, especially picker-to-parts systems, still dominate in Western Europe, accounting for approximately 80% of real-world applications and generating around 55% of warehouse operating costs [1, 2]. This process significantly influences operational efficiency, accuracy, and customer satisfaction. For small and medium-sized enterprises (SMEs), which often face growing product variety and limited resources, efficient and error-free picking is essential [3].
Picking systems can be divided into human-centered and machine-centered systems [2]. Human-centered approaches include picker-to-parts, put systems, and parts-to-picker strategies. In contrast, machine-based systems involve automated technologies such as vertical lift modules, A-frames, and robotic arms. Manual systems are typically organized using discrete, batch, wave, or zone-based picking strategies [3].
Paper-based picking systems remain common, particularly among SMEs, due to their simplicity and low implementation costs. In these systems, workers retrieve items using printed pick lists, sometimes augmented by barcode scanning or basic Warehouse Management Systems (WMS). Despite this, error rates range between 3% and 5% [4, 5]. These systems are also limited in terms of scalability and real-time accuracy. As of 2015, approximately 60% of U.S. distribution centers continued to use paper-based systems [6], highlighting their continued relevance [7, 8].
This paper first examines existing digital picking systems, analyzing their error reduction capabilities versus their implementation costs, with an emphasis on SME accessibility challenges. It then introduces vision-based AI (using computer vision models) for low-cost real-time verification, demonstrated through Case Study 1.
Next, it explores Large Language Models (LLMs) for adaptive guidance and multilingual interaction within the new “Multimodal Assistance” framework. These technologies converge in a vision-language synergy—combining AI “eyes” (vision) and “brain” (LLM) for error prevention—experimentally validated through the multimodal SOPHIE prototype (case study 2). The conclusion discusses their combined potential for intelligent, cost-effective picking systems.
Digital worker assistance systems in manual picking
Digital assistance systems are designed to support workers either cognitively or physically. They can be grouped into three categories. The first category is cognitive support systems (like pick-by-light, pick-by-scan, pick-by-voice and augmented reality headsets), the second category comprises training systems (for example virtual reality simulations), and the third category consists of motoric support tools (for example exoskeletons and automated guided vehicles) [9]. This research focuses on cognitive support systems that assist workers in navigation and item selection.
Assistance systems demonstrate varying error rates. Paper-based systems result in an average of eleven errors per 1,000 picks (1.1%), Radio Frequency (RF) scanning systems average six (0.6%), pick-by-light systems fail four (0.4%) times, and pick-by-voice assistance systems just once (0.1%). Systems based on heads-up displays (HUDs) produce around eight errors (0.8%), while projection-based systems result in up to 11.8 errors (1.18%) [4, 10]. Each error incurs an average cost of approximately $27.50 [4], leading to significant daily expenses depending on volume. These differences are illustrated in Figure 1, which visualizes the error rates across commonly used picking systems [10].
![Figure 1: Average errors per 1,000 picked parts across various picking systems, adapted from [10].](https://industry-science.com/wp-content/uploads/2025/08/Siddiqui_I4S-4-25_Figure-1.jpg)
Implementation costs represent a significant hurdle for many SMEs. Paper-based systems are the most affordable, with estimated setup costs of around $50,000 for 25 users. RF scanning systems follow at approximately $110,000, HUDs at $170,000, pick-by-voice at $270,000, and pick-by-light systems exceed $370,000 [10]. Systems using projection technologies are assumed to fall within the HUD cost range. High acquisition and integration costs often prevent adoption, particularly in resource-constrained settings. Figure 2 illustrates the estimated implementation cost of different picking systems for 25 users.
Although existing technologies address specific needs, significant drawbacks prevent their widespread adoption. Pick-by-voice systems are efficient but affected by environmental noise and user fatigue [11-15]. Pick-by-light systems are rigid and sensitive to misplacement errors [11, 12, 16-18]. RF-based systems provide high accuracy but are ergonomically demanding and time-consuming [15, 17]. AR-based smart glasses and HUDs are expensive, require high technical infrastructure, and pose physical discomfort after prolonged use [9, 19-22].
![Figure 2: Estimated system price for 25 users across different picking systems, adapted from [10].](https://industry-science.com/wp-content/uploads/2025/08/Siddiqui_I4S-4-25_Figure-2.jpg)
Most small and mid-sized warehouses still pick orders with paper lists or simple barcode scans because newer guidance systems are expensive and hard to install [6-8]. Yet customers now expect faster service and fewer mistakes [23]. Low-cost cameras, portable computers, and voice or text interfaces offer a possible middle ground, but their joint use in everyday picking has received little attention. This review looks at these practical tools and asks how they might fit into current workflows, improve accuracy, and do so without heavy upfront investment.
Object detection models for assisting manual picking
In industrial environments, object detection has become a key technology in automating visual tasks such as quality control, tracking, and verification [24-27]. The ability to recognize and locate physical objects in an image frame (in a live stream for example) makes it especially useful for supporting manual picking processes [24].
Several real-time object detection algorithms are suitable for industrial use. Among them, the You Only Look Once (YOLO) model series [25, 28] offers an impressive balance of speed and accuracy, making it a suitable choice for fast-paced environments. Lighter versions like Tiny-YOLO and MobileNet-Single Shot MultiBox Detector (MobileNet-SSD) are well-suited for deployment on edge devices [29]. Another efficient alternative is EfficientDet, which deploys an innovative method called compound scaling to balance performance and computational load [30].
Transformer-based object detection models with enhanced reasoning capabilities, such as RT-DETR, are emerging, though they are typically slower. Recent studies have, however, demonstrated that they are capable of performing better than YOLO [31]. Nonetheless, for real-time feedback in production, YOLO-based models remain the most practical and widely adopted solution [24, 27].
In picking scenarios, object detection models have the potential to verify whether the correct item has been picked, whether it is positioned accurately, and whether any defects or anomalies are present. This type of real-time feedback can significantly improve accuracy and reduce errors without interrupting the workflow.
The first case study was designed to explore whether modern computer vision models (YOLO) can provide real-time part verification in a manual picking scenario using only low-cost hardware. The goal was to demonstrate the practicality, efficiency, and low implementation barrier of such a system for SMEs. Rather than developing a full-scale dataset or benchmark suite, the design focused on feasibility: fine-tuning YOLO on a small set of labeled images and validating whether it could guide picking actions reliably in a controlled lab setting.
Case Study 1: An experiment with object detection technology
To evaluate the feasibility of low-cost AI support for manual picking tasks, a compact prototype was developed using a standard webcam and the YOLO object detection model running on a laptop as extra hardware for the assistance system. The system was designed to verify whether parts were picked correctly and in the right sequence—capabilities that are typically limited to costly technologies such as pick-by-light, vision-guided robotics, or scan-based systems. The goal was to replicate these core functions using minimal resources suitable for small and medium sized enterprises (SMEs).
The prototype was deployed in a lab environment to support drone assembly, as shown in Figure 3c, with parts organized in labeled KANBAN bins and a predefined pick sequence: first, a body cover, followed by a baseplate. The setup includes an overhead webcam above an assembly tray, a workstation with an NVIDIA RTX A1000 GPU, and a display guiding the picker through the task. The user interface displays the current part to pick (for example “Kommissionieren: Haube grün V1” (engl: “Commission: Body cover green V1”)) and updates in real time as detections occur.

When a picking task begins, the webcam captures frames that are streamed via WebSocket to the backend, as shown in Figure 3a. The GO backend publishes the frames to a Redis topic. A Python-based YOLO worker subscribes, performs inference, and returns two outputs: an annotated frame and the predicted part class. These are sent back via Redis, where the backend forwards the annotated image as an MJPEG stream and the part label via Server-Sent Events. The React frontend listens for these updates and compares the detected class to the expected sequence. If the part is correct, the system highlights it in green and advances to the next step. If not, a red warning is shown.
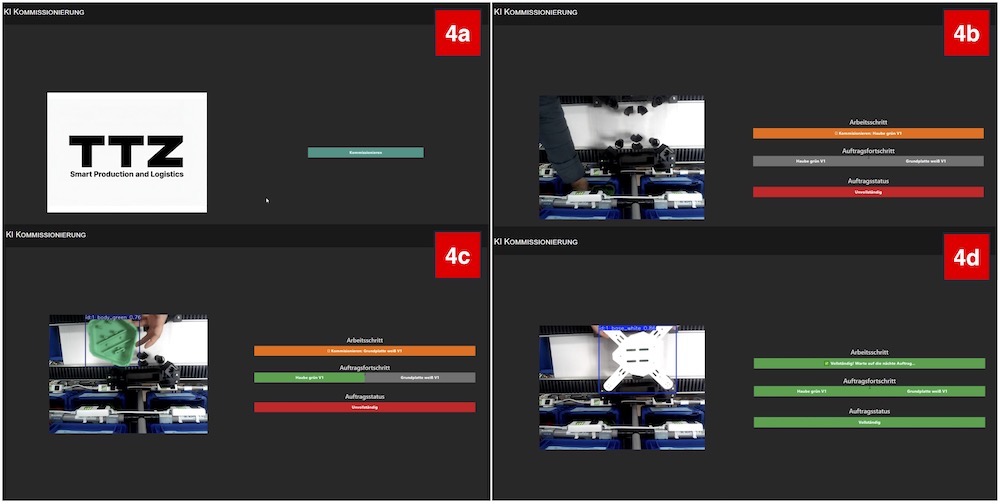
This progression is illustrated in Figure 4, which shows the full user interaction sequence from session start to task completion. In Figure 4a, the session begins with the start screen where the user launches a new picking task. In Figure 4b, the system instructs the worker to place “Haube grün V1”; both part progress indicators are grey, signaling that no item has yet been confirmed. In Figure 4c, the system detects and confirms the correct body cover, turning the indicator green and activating the next step—”Grundplatte weiß V1” (engl: “baseplate white V1”). Finally, in Figure 4d, after the correct baseplate is placed and validated, the system marks the task as complete, with all status indicators turning green.
This hands-free confirmation mechanism eliminates the need for manual scanning or button presses. The real-time verification logic is lightweight and decoupled across services using Redis as the communication backbone, ensuring low-latency response. The full architecture—frontend, backend, and detection pipeline—is summarized in Figure 3a.
Example images used for model training and validation are shown in Figure 3b, demonstrating reliable bounding box detection even under common lab conditions. The model was trained on approximately 2,000 labeled images across the nine relevant classes (various color variants of body cover and shape variants of baseplates).
Despite the modest dataset, it achieved strong classification performance. During live testing, the system maintained consistent responsiveness, with end-to-end detection latency—from camera frame capture to UI feedback—typically ranging between 100 and 300 milliseconds. The setup was realized at the Technology Transfer Center (TTZ) Leipheim, Germany [32], which supports research in smart production and logistics. The facility provides a complete test environment for drone order fulfillment. The selection of GO, Redis, and YOLO played a key role in building a modular, low-cost, and scalable prototype that runs on standard hardware.
The trained YOLOv8n model achieved high accuracy across all nine drone components. These included labels such as “Haube grün V1”, “Haube braun V2” (engl: “Body cover brown V2”), Haube orange V2 (engl: “Body cover orange V2”), Grundplatte weiß V1, Grundplatte blau V2 (engl: “Baseplate blue V2”), Grundplatte schwarz V1 (engl: “Baseplate black V1”), and other visually distinct body cover and baseplate variants.
As shown in Figure 5, training and validation losses consistently declined over 256 epochs. The model achieved a precision level of 99.6%, recall of near 100%, and mAP@0.5 of 99.2%, despite using no data augmentation. While these metrics reflect the model’s ability to correctly detect drone parts with high reliability, a real-world test is the key differentiator of actual performance.

The confusion matrix in Figure 6 shows accurate predictions for nearly all classes, with low confusion even between visually similar baseplate or body cover variants. These results confirm that the system can support reliable, low-cost picking guidance using consumer-grade webcams and minimal training data.

While the system achieved high accuracy under controlled lab conditions, a few limitations were observed. Under low light conditions, the model occasionally failed to detect the correct part or exhibited delayed responses. All training and validation images were captured in a well-lit environment, which may limit generalization to darker or more variable lighting scenarios. These findings suggest that consistent lighting or additional training data under varied conditions would be necessary to ensure robustness in real-world deployments. Image enhancement techniques will be explored in future iterations to ensure a more robust detection.
While conventional systems like pick-by-light or projection setups require infrastructure investments exceeding $170,000–$200,000 for 25 users, the case study prototype was implemented using consumer-grade components: a €70 webcam, a mid-tier laptop with an NVIDIA RTX A1000 GPU, and open-source software (YOLO). The only model training required was fine-tuning on ~2,000 labeled images, a task completed without augmentation and using standard Python libraries.
No commercial licenses were needed. Once deployed, inference is run entirely locally, eliminating cloud costs and ensuring data privacy. Operationally, the system showed latencies of 100 ms per frame and detected drone parts with 99.2% mAP@0.5. Thus, the solution demonstrates a practical, low-barrier alternative for SMEs seeking verification without the financial or technical burden of traditional systems.
This prototype and its initial findings were presented at the 2025 POMS Annual Conference in Atlanta [32], where the approach was recognized for its ease of deployment and potential for improving accuracy in manual workflows. While the prototype demonstrates practical feasibility, we acknowledge that a full cost-benefit analysis and systematic performance validation in diverse real-world environments remain necessary.
Multimodal assistance—Integrating vision and language models
Large Language Models (LLMs), based on the transformer architectures [33] and trained using massive text datasets, are capable of comprehending, processing, and generating human language [34]. These capabilities make them highly useful in the industrial context. Core capabilities in the industrial setting include Natural Language Understanding (NLU), text generation, reasoning and following instruction [34-36]. NLU helps to process different types of texts like technical manuals, operator logs, or regulatory documents [34]. Text generation is essential for automating the process of writing reports or generating documentation [34]. The reasoning capabilities of an LLM in an industrial setting are important for problem-solving, strategic planning and process optimization [37].
LLMs can follow user-defined instructions by enriching them with detailed contextual information via the usage of Retrieval-Augmented Generation (RAG) [36]. The usage of RAG is one method of transforming general-purpose LLMs into Industrial AI Systems. For reliable industrial deployment, LLMs must operate as task-specific agents that leverage contextual awareness and validate outputs against predefined rules [38]. Human-Machine Interfaces (HMIs) also benefit from the capabilities of LLMs. LLMs can replace complex menus in HMIs with a chat interface, where the worker can ask their questions via text or voice command, making the HMIs more accessible and intuitive [39, 40].
Building on the reliable detection and logic-driven guidance offered by object detection models, integrating LLMs introduces a new layer of adaptability and communication. In this multimodal setting, the vision model acts as the “eyes” of the system, ensuring physical accuracy [41], whereas the LLM acts as the “brain” and the “voice” of the system, providing context, reasoning and human-friendly interaction [37].
One key function of the LLM in the context of picking assistance could be to guide the worker via step-by-step instructions, which are generated from the order configuration (for example first part X, then part Y) and monitoring the worker completion steps in real time. The multilingual nature of LLMs combined with voice commands allows for the seamless interaction with workers from any background. The LLM can also help to train new employees with interactive tutorials, guide workers in case of an error, and create reports based on vision logs and order configuration [37].
Most of these LLM functionalities are closely connected to the outputs of the vision model and vice versa, creating a positive synergy. An exemplary workflow of this synergy is the error feedback loop: the vision model detects an error in the picking process and, subsequently, the LLM explains to the worker what the error is and how to fix it. Another synergy is the tracking of the assembly steps via parts verification by the vision model and the parallel generation of assembly instructions for the current step by the LLM. One synergy that leads to error prevention is the following: the vision model recognizes a frequent error pattern and, consequently, the LLM warns the worker preemptively to avoid this error [42].
This multimodal approach brings about multiple benefits. It reduces the cognitive load on the workers by guiding them through the process via voice commands [43]. The multimodality also turns the system from solely error detection to error prevention. By preventing errors and giving real-time guidance, the multimodal picking assistant accelerates the picking workflow [44].
Need for a real-time context-aware language assistant system
What if the picking assistant could do more than just detect parts? What if it could speak, clarify mistakes, and guide workers through each step in their own language? These questions led us to extend our vision-based system into something more interactive. In this section, we explore how combining object detection with a language model can create an assistant that not only sees what the worker is doing but also responds in real time with helpful feedback and instructions.
Case study 1 demonstrated that low-cost object detection models like YOLO can effectively verify pick sequences in real time using modest hardware. However, while visual verification ensures correctness, it does not address the broader operational challenges SMEs face—namely, onboarding new or temporary workers, navigating language barriers, and coping with a retiring workforce. Traditional retraining approaches are time-consuming and often ineffective across multilingual teams.
At the same time, intelligent assistance systems in recent literature largely depend on cloud-based LLMs and infrastructure-heavy setups [45, 46], which are incompatible with resource-constrained environments. There remains a clear gap between the practical, real-time needs of small-scale manufacturing and the assumptions embedded in most AI tooling.
What is needed is a system that offers not just visual verification but interactive, multilingual support that aligns with each stage of the task. In the next section, we explore SOPHIE—our lightweight multimodal assistant that combines local YOLO detection with a context-aware LLM. SOPHIE not only understands the current order but is also aware of the worker’s progress, enabling dynamic support on demand for each individual step without relying on cloud services.
The second case study extends the first by integrating a local large language model (LLM) into the picking workflow. The design aimed to explore whether combining vision with contextual language understanding could provide real-time, multilingual user support without relying on cloud infrastructure. The LLM was not retrained but operated on structured prompts derived from the current order and detection state. The study focused on scope expansion, user interaction, and demonstrating low-cost deployment using off-the-shelf hardware.
Case Study 2: An experiment on the synergies between vision and language
To validate our ideas on the combination of vision and language, we implemented a prototype application (SOPHIE) on top of case study 1, which combines the vision model trained for case study 1 with a local LLM (WizardLM2) [47]. The idea of SOPHIE is that the LLM answers real-time queries from the user based on the current order and the part detected by the YOLO model.
SOPHIE is implemented as a Tkinter [48] application, shown in Figure 7, which consists of a camera stream with extra information (FPS, camera in use, start time etc.), a confidence threshold slider for the detection of parts with the YOLO model, a thumbnail and text for the currently expected part, an overview over the whole order with its part sequence and a button for opening the chat popup with the LLM. In the chat popup, the user can either select predefined questions in German and English relevant to the picking task or can ask their own questions [48]. To generate a meaningful response, the LLM is given a prompt that is a combination of different types of contexts.

The base of the prompt is the system prompt, which stays the same for all queries and tells the LLM its task (multilingual assistant for drone assembly), how it should answer (concise and precise, language-awareness) and that it should use all given context. The context starts with information about the order and its status.
The order confirmation comprises the order ID, the expected body cover and the expected baseplate, while the status tells the LLM which parts are already verified, which is expected next and if any wrong detections have occurred. The next context segment in the prompt consists of instructions for picking either the body cover or baseplate depending on which part is currently expected. The final piece of context is the user’s actual question.

The answers generated by SOPHIE, such as those in Figure 8, show that, by combining different contexts in the prompt, the system can guide the user through the picking process and help them in case of a picking error. The SOPHIE interface demonstrates four common interaction stages during the picking process, shown in Figure 8. In Figure 8a, the user initiates assistance via button or simulated voice input.
Figure 8b presents predefined multilingual questions; here, the user selects a German prompt and receives a German response. In Figure 8c, the user chooses option 0 to enter a custom question manually, this time in English. Figure 8d shows SOPHIE’s context-aware response in English, highlighting its ability to seamlessly handle language switching based on user input.
Extending capability with LLM assistance at minimal overhead
While combining NLP and vision is often assumed to be resource-intensive, SOPHIE was designed for feasibility and accessibility. The application is built entirely in Python using Tkinter and runs on the same consumer-grade hardware as case study 1 (4 GB Nvidia GPU, 32 GB RAM). The language component (WizardLM2) [47] is a pre-trained, open-source LLM running locally without fine-tuning. This avoids expensive training cycles or server-based inference.
Although the LLM response time (~20-30 seconds per query) is slower than optimal, this is a trade-off made for offline operation, data privacy, and cost control. All core functionalities such as visual validation, multilingual support, and contextual task guidance are achieved without requiring additional licenses or cloud infrastructure.
As such, SOPHIE represents a practical extension of vision-based picking systems, making interactive assistance more inclusive and adaptable in constrained industrial environments. While the prototype demonstrates practical feasibility, we acknowledge that a full cost-benefit analysis and systematic performance validation in diverse real-world environments remain future work.
Toward smarter order picking
The comparison of existing assistance systems highlights a clear trade-off between error rates and implementation costs, often limiting accessibility for many organizations. Our first case study demonstrated that reliable part verification and sequencing can already be achieved using computer vision models and simple logic, implemented with low-cost, widely available hardware.
At the same time, recent developments in generative AI, especially Large Language Models, offer new possibilities to enhance interaction, adaptability, and multilingual accessibility. Our second case study shows combining vision with language models has the potential to improve the guidance of the picker and thus reduce the error rates. Together, these technologies have the potential to complement or gradually replace traditional systems by offering scalable, intelligent, and cost-effective alternatives.
Bibliography
[1] Grosse, E. H.; Glock, C. H.; Jaber, M. Y.; Neumann, W. P.: Incorporating human factors in order picking planning models: framework and research opportunities. In: International Journal of Production Research 53 (2015) 3, pp. 695-717. DOI: https://doi.org/10.1080/00207543.2014.919424.[2] De Koster, R.; Le-Duc, T.; Roodbergen, K. J.: Design and control of warehouse order picking: A literature review. In: European journal of operational research 182 (2007) 2, pp. 481-501. DOI: https://doi.org/10.1016/j.ejor.2006.07.009.
[3] Casella, G.; Volpi, A.; Montanari, R.; Tebaldi, L.; Bottani, E.: Trends in order picking: A 2007–2022 review of the literature. In: Production & Manufacturing Research 11 (2023) 1, p. 2191115. DOI: https://doi.org/10.1080/21693277.2023.2191115.
[4] Łopuszyński, M.; Janusz, K.; Karwat, D.: Comparative Study of Selected Order-Picking Methods: Efficiency, Ergonomics, and Adaptation Rate of New Employees. In: Sensors 25 (2025) 3, pp. 923. DOI: https://doi.org/10.3390/s25030923.
[5] Li, F.: Comparing pick-by-vision to pick-by-paper: An experimental assessment of pick times, error rates and user satisfaction. Hochschule für angewandte Wissenschaften Neu-Ulm 2020. URL: https://publications.hs-neu-ulm.de/1750/1/Kunze_Fang_WP_42_Comparing%20pick%20by%20vision%20to%20pick%20by%20paper.pdf, accessed 14.05.2025.
[6] UNEX: Paper Picking Processes: Are They Picking Your Pocket? URL: https://blog.unex.com/paper-picking-processes, accessed 14.05.2025.
[7] Schriefer, J.: Why Do The Majority Of DCs Still Use Paper For Picking? URL: https://www.lucasware.com/blog-majority-dcs-still-use-paper-picking/, accessed 14.05.2025.
[8] orderwise: Why paper-picking is picking the pockets of your warehouse. URL: https://orderwise.co.uk/en/blog/why-paper-picking-is-picking-the-pockets-of-your-warehouse, accessed 14.05.2025.
[9] Lucchese, A.; Mummolo, G.: Human-Centric Assistive Technologies in Manual Picking and Assembly Tasks: A Literature Review. In: Management and Production Engineering Review 15 (2024) 2, pp. 73-86. DOI: https://doi.org/10.24425/mper.2024.151132.
[10] Mandar, E. M.; Dachry, W.; Bensassi, B.: Toward a Real-Time Picking Errors Prevention System Based on RFID Technology. In: Advances on Smart and Soft Computing (2021), Singapore, pp. 303-318. DOI: https://doi.org/10.1007/978-981-15-6048-4_27.
[11] Amit, J.: Voice Picking Systems: Are They The Best Choice for Your Warehouse? URL: https://aiola.ai/blog/voice-picking-systems, accessed 14.05.2025.
[12] Badwi, M.: Voice picking or pick to light: which is best for your business? URL: https://www.scjunction.com/blog/voice-picking-or-pick-to-light-which-is-best-for-your-business, accessed 14.05.2025.
[13] Guest: 3 things to know before investing in voice picking. URL: https://www.allthingssupplychain.com/3-things-to-know-before-investing-in-voice-picking/, accessed 14.05.2025.
[14] Markowitz, J.: Ergonomics of the Voice. URL: https://www.speechtechmag.com/Articles/Columns/Forward-Thinking/Ergonomics-of-the-Voice-34400.aspx, accessed 14.05.2025.
[15] Stipp, T.: Comparing Order Picking Technologies. URL: https://www.procatdt.com/wp-content/uploads/2021/01/Comparing-Order-Picking-Technologies.pdf, accessed 14.05.2025.
[16] Yzquierdo, J.: What is a Pick to Light System and How Does Voice Compare? URL: https://www.lucasware.com/what-is-a-pick-to-light-system-and-how-does-voice-compare/, accessed 15.05.2025.
[17] Hanrahan, D.: Multi-modal picking technology provides ROI for small to mid size order fulfillment processes. URL: https://parcelindustry.com/print-article-1322-permanent.html, accessed 14.05.2025.
[18] Packiyo: Pick to Light System explained: All you need to know. URL: https://www.packiyo.com/blog/pick-to-light, accessed 14.05.2025.
[19] Ames, B.: Smartglasses get a second look from warehouses. URL: https://www.dcvelocity.com/articles/28603-smartglasses-get-a-second-look-from-warehouses, accessed 14.05.2025.
[20] Schriefer, J.: The reality of smart glasses for warehouse vision picking. URL: https://www.lucasware.com/warehouse-vision-picking/, accessed 28.03.2025.
[21] Heuts, P.: DHL experiments with augmented reality. 2017. URL: https://www.etui.org/sites/default/files/Hesamag_16_EN-22-26.pdf, accessed 28.03.2025.
[22] Herzog, N. V.; Beharic, A.: Effects of the use of smart glasses on eyesight. In: Human Systems Engineering and Design II: Proceedings of the 2nd International Conference on Human Systems Engineering and Design (IHSED2019): Future Trends and Applications, September 16-18, 2019, Universität der Bundeswehr München, Munich, Germany (2020), pp. 808-812. DOI: https://doi.org/10.1007/978-3-030-27928-8_123.
[23] Lai, K.-h.; Cheng, T. E.: Just-in-time logistics. London 2016.
[24] Khanam, R.; Hussain, M.; Hill, R.; Allen, P.: A comprehensive review of convolutional neural networks for defect detection in industrial applications. In: IEEE Access 12 (2024) pp. 94250-94295. DOI: https://doi.org/10.1109/ACCESS.2024.3425166.
[25] Vijayakumar, A.; Vairavasundaram, S.: Yolo-based object detection models: A review and its applications. In: Multimedia Tools and Applications 83 (2024) 35, pp. 83535-83574. DOI: https://doi.org/10.1007/s11042-024-18872-y.
[26] Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J.: Object detection in 20 years: A survey. In: Proceedings of the IEEE 111 (2023) 3, pp. 257-276. DOI: https://doi.org/10.48550/arXiv.1905.05055.
[27] Ahmad, H. M.; Rahimi, A.: Deep learning methods for object detection in smart manufacturing: A survey. In: Journal of Manufacturing Systems 64 (2022) pp. 181-196. DOI: https://doi.org/10.1016/j.jmsy.2022.06.011.
[28] Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A.: You Only Look Once: Unified, Real-Time Object Detection. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016), pp. 779-788. DOI: https://doi.org/10.1109/CVPR.2016.91.
[29] Sekar, K.; Dheepa, T.; Sheethal, R.; Suvarna Smita, R.; Teja, V. D.: Efficient Object Detection on Low-Resource Devices Using Lightweight MobileNet-SSD. In: 2025 International Conference on Intelligent Systems and Computational Networks (ICISCN) (2025), Bangalore, pp. 1-6. DOI: https://doi.org/10.1109/ICISCN64258.2025.10934442.
[30] Tan, M.; Pang, R.; Le, Q. V.: Efficientdet: Scalable and efficient object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2020), pp. 10781-10790. DOI: https://doi.org/10.1109/CVPR42600.2020.01079.
[31] Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; et al.: Detrs beat yolos on real-time object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024), pp. 16965-16974. DOI: https://doi.org/10.48550/arXiv.2304.08069.
[32] Siddiqui, M. K.; Hoffman, B.; Grinninger, J.: Real-Time Object Detection using AI for Enhanced Operational Efficiency. Presented at the 2025 POMS Annual Conference, Atlanta, May 8–12.
[33] Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; et al.: Attention is all you need. In: Advances in neural information processing systems 30 (2017).
[34] Zhao, W. X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; et al.: A survey of large language models. In: Journal (2023). DOI: https://doi.org/10.48550/arXiv.2303.18223.
[35] Wasti, S. M.; Pu, K. Q.; Neshati, A.: Large Language User Interfaces: Voice Interactive User Interfaces powered by LLMs. In: Intelligent Systems Conference (2024), pp. 639-655.
[36] Xia, Y.; Jazdi, N.; Weyrich, M.: Applying Large Language Models for intelligent industrial automation. In: atp magazin 66 (2024) 6–7, pp. 62-71. DOI: https://doi.org/10.17560/atp.v66i6-7.2739.
[37] Li, Y.; Zhao, H.; Jiang, H.; Pan, Y.; Liu, Z.; et al.: Large language models for manufacturing. In: Journal (2024). DOI: https://doi.org/10.48550/arXiv.2410.21418.
[38] Halse, G.: Beyond the Prompt: Harnessing Industrial AI Agents for Reliable Automation. URL: https://www.gavinhalse.com/ai-in-manufacturing/beyond-the-prompt-harnessing-industrial-ai-agents-for-reliable-automation/, accessed 15.05.2025.
[39] Shone, O.: 5 key features and benefits of large language models. URL: https://www.microsoft.com/en-us/microsoft-cloud/blog/2024/10/09/5-key-features-and-benefits-of-large-language-models/, accessed 14.05.2025.
[40] Kaur, J.: Enhancing Manufacturing with Large Language Models (LLMs). URL: https://www.xenonstack.com/blog/large-language-model-manufacturing, accessed 15.05.2025.
[41] Admon, W.: Intelligent Humanoid Robots: An Overview and Focus on Visual Perception Systems. URL: https://www.basic.ai/blog-post/intelligent-humanoid-robots-vision-perception, accessed 15.05.2025.
[42] Mikołajewska, E.; Mikołajewski, D.; Mikołajczyk, T.; Paczkowski, T.: Generative AI in AI-Based Digital Twins for Fault Diagnosis for Predictive Maintenance in Industry 4.0/5.0. In: Applied Sciences 15 (2025) 6, p. 3166. DOI: https://doi.org/10.3390/app15063166.
[43] Gkintoni, E.; Antonopoulou, H.; Sortwell, A.; Halkiopoulos, C.: Challenging Cognitive Load Theory: The Role of Educational Neuroscience and Artificial Intelligence in Redefining Learning Efficacy. In: Brain Sciences 15 (2025) 2, p. 203. DOI: https://doi.org/10.3390/brainsci15020203.
[44] Peiu, B.: Transforming quality control: How AI-powered visual anomaly detection reduces production defects. URL: https://www.craftworks.ai/insights/know-how/transforming-quality-control-how-ai-powered-visual-anomaly-detection-reduces-production-defects/, accessed 15.05.2025.
[45] Wang, H.; Li, C.; Li, Y.-F.; Tsung, F.: An Intelligent Industrial Visual Monitoring and Maintenance Framework Empowered by Large-Scale Visual and Language Models. In: IEEE Transactions on Industrial Cyber-Physical Systems (2024).
[46] Giacalone, E.: AI-Powered Autonomous Industrial Monitoring: Integrating Robotics, Computer Vision, and Generative AI. 2025, Politecnico di Torino.
[47] ollama.com: wizardlm2. URL: https://ollama.com/library/wizardlm2, accessed 26.06.2025.
[48] Love, D.: Tkinter GUI Programming by Example: Learn to create modern GUIs using Tkinter by building real-world projects in Python. 2018.
Your downloads
Solutions: Logistics Logistics Technology






