


Die manuelle Kommissionierung technologisch unterstützen |
Von herkömmlichen Pick-by-Systemen zur KI-gesteuerten manuellen Kommissionierhilfe
| Zeitschrift | Industry 4.0 Science |
| Ausgabe | 41. Jahrgang, 2025, Ausgabe 4, Seite 6-19 |
| Open Access | https://doi.org/10.30844/I4SD.25.4.6 |
| Literatur | Teilen | Zitieren | Download |
Abstract
Keywords
Artikel
Mit der fortschreitenden Automatisierung in der Industrie 4.0 werden viele industrielle Prozesse neu definiert. Dennoch ist die Kommissionierung nach wie vor stark auf menschliche Arbeitskräfte angewiesen. Warum ist diese Aufgabe nach wie vor so sehr auf den Menschen ausgerichtet? Und wie können neue Technologien die Rolle des Menschen verbessern, anstatt sie zu ersetzen? In diesem Artikel werden diese Fragen untersucht und neue Wege aufgezeigt, die Wahrnehmungs- und sprachbasierte Technologien miteinander kombinieren.
Die Auftragskommissionierung (OP) ist nach wie vor einer der kostenintensivsten und fehleranfälligsten Prozesse in der Lager- und Montagelogistik. In Westeuropa dominieren immer noch manuelle Ansätze, insbesondere Picker-to-Parts-Systeme, die etwa 80 % der realen Anwendungen ausmachen und rund 55 % der Lagerbetriebskosten verursachen [1, 2]. Dieser Prozess hat einen erheblichen Einfluss auf die betriebliche Effizienz, die Genauigkeit und die Kundenzufriedenheit. Für kleine und mittlere Unternehmen (KMU), die häufig mit einer wachsenden Produktvielfalt und begrenzten Ressourcen konfrontiert sind, ist eine effiziente und fehlerfreie Kommissionierung von wesentlicher Bedeutung [3].
Kommissioniersysteme lassen sich in menschenzentrierte und maschinenzentrierte Systeme unterteilen [2]. Zu den menschenzentrierten Ansätzen gehören Picker-to-Parts, Put-Systeme und Parts-to-Picker-Strategien. Im Gegensatz dazu werden bei maschinenbasierten Systemen automatisierte Technologien wie vertikale Hubmodule, A-Rahmen und Roboterarme eingesetzt. Manuelle Systeme sind in der Regel mit diskreten, Batch-, Wellen- oder zonenbasierten Kommissionierstrategien organisiert [3].
Papierbasierte Kommissioniersysteme sind aufgrund ihrer Einfachheit und der geringen Implementierungskosten nach wie vor weit verbreitet, insbesondere bei KMU. Bei diesen Systemen entnehmen die Mitarbeiter die Artikel anhand gedruckter Kommissionierlisten, die manchmal durch Barcode-Scanning oder einfache Lagerverwaltungssysteme (LVS) ergänzt werden. Trotzdem liegen die Fehlerquoten zwischen 3 % und 5 % [4, 5]. Diese Systeme sind auch in Bezug auf Skalierbarkeit und Echtzeitgenauigkeit begrenzt. Im Jahr 2015 nutzten etwa 60 % der US-amerikanischen Distributionszentren weiterhin papierbasierte Systeme [6], was ihre anhaltende Bedeutung unterstreicht [7, 8].
In diesem Beitrag werden zunächst die bestehenden digitalen Kommissioniersysteme untersucht und ihre Fähigkeiten zur Fehlerreduzierung im Vergleich zu den Implementierungskosten analysiert, wobei der Schwerpunkt auf den Herausforderungen der Zugänglichkeit für KMU liegt. Anschließend wird die bildverarbeitungsbasierte KI (unter Verwendung von Bildverarbeitungsmodellen) für eine kostengünstige Echtzeitüberprüfung vorgestellt, die anhand der Fallstudie 1 demonstriert wird.
Als Nächstes werden große Sprachmodelle (Large Language Models, LLMs) für adaptive Führung und mehrsprachige Interaktion im Rahmen der neuen “Multimodalen Unterstützung” untersucht. Diese Technologien konvergieren in einer Vision-Sprache-Synergie – einer Kombination aus KI-„Augen“ (Vision) und KI-„Gehirn“ (LLM) zur Fehlervermeidung – die experimentell durch den multimodalen SOPHIE-Prototyp (Fallstudie 2) validiert wurde. In der Schlussfolgerung wird ihr kombiniertes Potenzial für intelligente, kostengünstige Kommissioniersysteme erörtert.
Digitale Assistenzsysteme für die manuelle Kommissionierung
Digitale Assistenzsysteme sind so konzipiert, dass sie die Mitarbeiter entweder kognitiv oder physisch unterstützen. Sie können in drei Kategorien eingeteilt werden [9]: 1) kognitive Unterstützungssysteme (wie Pick-by-Light, Pick-by-Scan, Pick-by-Voice, Augmented-Reality-Headsets), 2) Trainingssysteme (z. B. Virtual-Reality-Simulationen) und 3) motorische Unterstützungswerkzeuge (z. B. Exoskelette, fahrerlose Transportsysteme). Diese Forschung konzentriert sich auf kognitive Unterstützungssysteme, die den Arbeitern bei der Navigation und der Auswahl von Gegenständen helfen.
Assistenzsysteme weisen unterschiedliche Fehlerquoten auf. Papierbasierte Systeme führen zu durchschnittlich 11 Fehlern pro 1000 Entnahmen (1,1 %), RF-Scansysteme zu durchschnittlich 6 Fehlern (0,6 %), Pick-by-Light-Systeme zu 4 Fehlern (0,4 %) und Pick-by-Voice-Assistenzsysteme zu 1 Fehler (0,1 %). Systeme, die auf Heads-up-Displays (HUDs) basieren, verursachen etwa 8 Fehler (0,8 %), während projektionsbasierte Systeme bis zu 11,8 Fehler (1,18 %) verursachen [4, 10]. Jeder Fehler verursacht im Durchschnitt Kosten von ca. 27,50 US-Dollar [4], was je nach Umfang zu erheblichen täglichen Kosten führt. Diese Unterschiede werden in Bild 1 veranschaulicht, in der die Fehlerquoten der gängigen Kommissioniersysteme dargestellt sind [10].
![Bild 1: Durchschnittliche Fehler pro 1000 kommissionierte Teile bei verschiedenen Kommissioniersystemen (angepasst aus [10]).](https://industry-science.com/wp-content/uploads/2025/08/Siddiqui_I4S-25-4_Bild-1.jpg)
Die Einführungskosten stellen für viele KMU eine große Hürde dar. Am erschwinglichsten sind papierbasierte Systeme mit geschätzten Einrichtungskosten von etwa 50 000 US-Dollar für 25 Benutzer. RF-Scansysteme folgen mit etwa 110 000 US-Dollar, HUDs mit 170 000 US-Dollar, Pick-by-Voice mit 270 000 US-Dollar und Pick-by-Light-Systeme mit über 370 000 US-Dollar [10]. Bei Systemen, die Projektionstechnologien verwenden, wird davon ausgegangen, dass sie in den Kostenbereich von HUDs fallen. Hohe Anschaffungs- und Integrationskosten verhindern häufig die Einführung, insbesondere in ressourcenbeschränkten Umgebungen. Bild 2 veranschaulicht die geschätzten Implementierungskosten verschiedener Kommissioniersysteme für 25 Benutzer.
Obwohl die vorhandenen Technologien spezifische Anforderungen erfüllen, verhindern erhebliche Nachteile ihre breite Einführung. Pick-by-Voice-Systeme sind effizient, werden aber durch Umgebungsgeräusche und Ermüdung der Benutzer beeinträchtigt [11–15]. Pick-by-Light-Systeme sind starr und anfällig für Fehler bei der Platzierung [11, 12, 16–18]. RF-basierte Systeme bieten eine hohe Genauigkeit, sind aber ergonomisch anspruchsvoll und zeitaufwändig [15, 17]. AR-basierte Smart Glasses und HUDs sind teuer, erfordern eine hohe technische Infrastruktur und sind bei längerem Gebrauch körperlich unangenehm [9, 19–22].
![Bild 2: Geschätzter Systempreis für 25 Benutzer in verschiedenen Kommissioniersystemen (angepasst aus [10]).](https://industry-science.com/wp-content/uploads/2025/08/Siddiqui_I4S-25-4_Bild-2.jpg)
Der Bedarf an einem erschwinglichen Echtzeit-Überprüfungssystem
Die meisten kleinen und mittelgroßen Lagerhäuser kommissionieren immer noch mit Papierlisten oder einfachen Barcode-Scans, weil neuere Leitsysteme teuer und schwer zu installieren sind [6–8]. Dabei erwarten die Kunden heute einen schnelleren Service und weniger Fehler [23]. Kostengünstige Kameras, tragbare Computer und Sprach- oder Textschnittstellen bieten einen möglichen Mittelweg, aber ihr gemeinsamer Einsatz in der alltäglichen Kommissionierung wurde bisher kaum beachtet. In diesem Beitrag werden diese praktischen Hilfsmittel untersucht und die Frage gestellt, wie sie sich in die aktuellen Arbeitsabläufe einfügen, die Genauigkeit erhöhen und dies ohne große Vorabinvestitionen erreichen können.
Objekterkennungsmodelle zur Unterstützung der manuellen Kommissionierung
In industriellen Umgebungen hat sich die Objekterkennung zu einer Schlüsseltechnologie für die Automatisierung visueller Aufgaben wie Qualitätskontrolle, Verfolgung und Überprüfung entwickelt [24–27]. Ihre Fähigkeit, physische Objekte in einem Bildrahmen (z. B. in einem Live-Stream) zu erkennen und zu lokalisieren, macht sie besonders nützlich für die Unterstützung manueller Kommissionierungsprozesse [24].
Mehrere Algorithmen zur Objekterkennung in Echtzeit sind für den industriellen Einsatz geeignet. Unter ihnen bietet die You Only Look Once (YOLO)-Modellreihe [25, 28] ein beeindruckendes Gleichgewicht zwischen Geschwindigkeit und Genauigkeit, was sie zu einer geeigneten Wahl für schnelllebige Umgebungen macht. Leichtere Versionen wie Tiny-YOLO und MobileNet-Single Shot MultiBox Detector (MobileNet-SSD) eignen sich gut für den Einsatz auf Endgeräten [29].
Eine weitere effiziente Alternative ist EfficientDet, das eine innovative Methode namens Compound Scaling einsetzt, um Leistung und Rechenlast auszugleichen [30]. Transformer-basierte Objekterkennungsmodelle wie RT-DETR sind mit erweiterten Argumentationsfähigkeiten auf dem Vormarsch, obwohl sie in der Regel langsamer sind, zeigen neuere Studien, dass sie eine bessere Leistung als YOLO erreichen können [31]. Für Echtzeit-Feedback in der Produktion sind YOLO-basierte Modelle nach wie vor die praktischste und am weitesten verbreitete Lösung [24, 27].
In Kommissionierungsszenarien haben Objekterkennungsmodelle das Potenzial, zu überprüfen, ob der richtige Artikel entnommen wurde, ob er genau positioniert ist und ob irgendwelche Defekte oder Anomalien vorhanden sind. Diese Art von Echtzeit-Feedback kann die Genauigkeit erheblich verbessern und Fehler reduzieren, ohne den Arbeitsablauf zu unterbrechen.
In der ersten Fallstudie sollte untersucht werden, ob moderne Computer-Vision-Modelle (YOLO) in einem manuellen Kommissionierungsszenario mit preiswerter Hardware eine Teileüberprüfung in Echtzeit ermöglichen können. Ziel war es, die Praktikabilität, Effizienz und niedrige Implementierungshürde eines solchen Systems für KMU zu demonstrieren. Anstatt einen vollständigen Datensatz oder eine Benchmark-Suite zu entwickeln, konzentrierte sich der Entwurf auf die Machbarkeit: Feinabstimmung von YOLO auf einem kleinen Satz beschrifteter Bilder und Validierung, ob es die Kommissionierung in einer kontrollierten Laborumgebung zuverlässig anleiten kann.
Fallstudie 1: Ein Experiment mit Objekterkennungstechnologie
Um die Machbarkeit einer kostengünstigen KI-Unterstützung für manuelle Kommissionieraufgaben zu untersuchen, haben wir einen kompakten Prototyp entwickelt, der eine Standard-Webcam und das YOLO-Objekterkennungsmodell auf einem Laptop als zusätzliche Hardware für das Assistenzsystem verwendet. Das System sollte überprüfen, ob die Teile korrekt und in der richtigen Reihenfolge entnommen wurden – Fähigkeiten, die normalerweise auf kostspielige Technologien wie Pick-by-Light, visionsgeführte Robotik oder scanbasierte Systeme beschränkt sind.
Unser Ziel war es, diese Kernfunktionen mit minimalen Ressourcen zu replizieren, die für kleine und mittlere Unternehmen (KMU) geeignet sind. Der Prototyp wurde in einer Laborumgebung eingesetzt, wie in Bild 3c gezeigt, um die Montage von Drohnen zu unterstützen, wobei die Teile in beschrifteten KANBAN-Behältern und einer vordefinierten Entnahmereihenfolge organisiert wurden: zuerst eine Karosserieabdeckung (Haube), gefolgt von einer Grundplatte.
Wie in Bild 3c gezeigt, umfasst der Aufbau eine Overhead-Webcam über einem Montagefach, eine Workstation mit einer NVIDIA RTX A1000 GPU und ein Display, das den Kommissionierer durch die Aufgabe führt. Die Benutzeroberfläche zeigt das aktuell zu entnehmende Teil an (z. B. „Kommissionieren: Haube grün V1“) und wird in Echtzeit aktualisiert, sobald eine Erkennung stattfindet.

Wenn eine Kommissionieraufgabe beginnt, nimmt die Webcam Bilder auf, die über WebSocket an das Backend gestreamt werden (Bild 3a). Das GO-Backend veröffentlicht die Bilder in einem Redis-Topic. Ein Python-basierter YOLO-Worker meldet sich an, führt eine Inferenz durch und gibt zwei Ergebnisse zurück: einen kommentierten Frame und die vorhergesagte Teilklasse. Diese werden über Redis zurückgeschickt, wobei das Backend das kommentierte Bild als MJPEG-Stream und das Teile-Label über Server-Sent Events weiterleitet. Das React-Frontend lauscht auf diese Updates und vergleicht die erkannte Klasse mit der erwarteten Sequenz. Wenn das Teil korrekt ist, wird es grün markiert und der nächste Schritt wird eingeleitet. Wenn nicht, wird eine rote Warnung angezeigt.
Dieser Ablauf wird in Bild 4 veranschaulicht, die den gesamten Ablauf der Benutzerinteraktion vom Beginn der Sitzung bis zum Abschluss der Aufgabe zeigt. In Bild 4a beginnt die Sitzung mit dem Startbildschirm, auf dem der Benutzer eine neue Kommissionieraufgabe startet. In Bild 4b weist das System den Mitarbeiter an, Haube grün V1 zu platzieren; beide Teilfortschrittsanzeigen sind grau, was bedeutet, dass noch kein Artikel bestätigt wurde. In Bild 4c erkennt und bestätigt das System die richtige Haube (Körper), wodurch die Anzeige grün wird, und der nächste Schritt aktiviert wird – Grundplatte weiß V1. In Bild 4d schließlich, nachdem die richtige Grundplatte platziert und bestätigt wurde, markiert das System die Aufgabe als abgeschlossen, wobei alle Statusanzeigen grün leuchten.
Dieser freihändige Bestätigungsmechanismus macht das manuelle Scannen oder Drücken von Tasten überflüssig. Die Echtzeit-Prüflogik ist leichtgewichtig und über Dienste hinweg entkoppelt, wobei Redis als Kommunikations-Backbone verwendet wird, um eine niedrige Latenzzeit zu gewährleisten. Die vollständige Architektur – Frontend, Backend und Erkennungspipeline – ist in Bild 3a zusammengefasst.
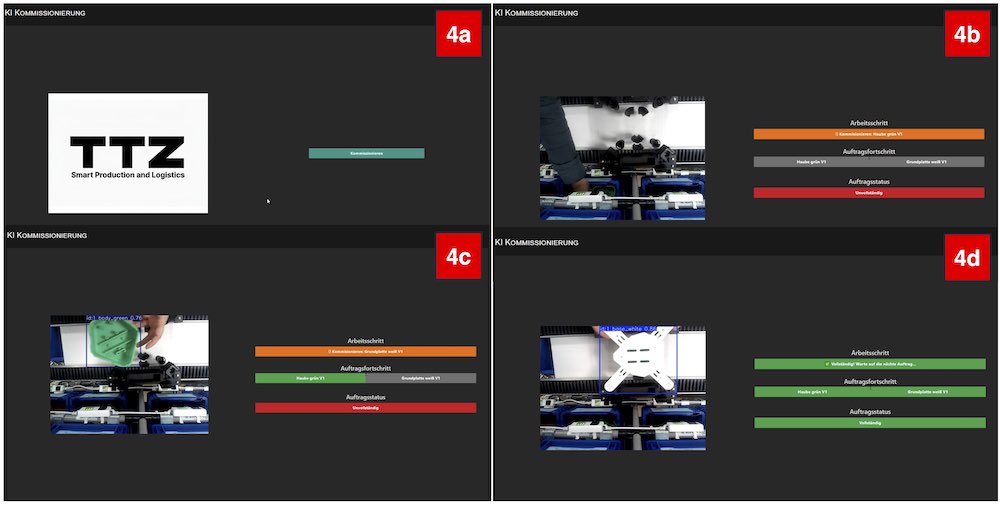
Bild 3b zeigt Beispielbilder, die für das Training und die Validierung des Modells verwendet wurden und die zuverlässige Erkennung von Bounding Boxes auch unter normalen Laborbedingungen demonstrieren. Das Modell wurde auf etwa 2000 beschrifteten Bildern aus den neun relevanten Klassen (verschiedene Farbvarianten von Naben und Formvarianten von Tellern) trainiert. Trotz der bescheidenen Größe des Datensatzes erzielte es eine starke Klassifizierungsleistung.
Während der Live-Tests zeigte das System eine gleichbleibende Reaktionsfähigkeit mit einer durchgehenden Erkennungslatenz – von der Erfassung des Kamerabildes bis zum UI-Feedback –, die typischerweise zwischen 100 und 300 Millisekunden lag. Der Aufbau wurde im Technologietransferzentrum (TTZ) Leipheim [32] realisiert, das die Forschung im Bereich intelligente Produktion und Logistik unterstützt. Die Einrichtung bietet eine komplette Testumgebung für die Auftragsabwicklung per Drohne. Die Auswahl von GO, Redis und YOLO spielte eine Schlüsselrolle beim Aufbau eines modularen, kostengünstigen und skalierbaren Prototyps, der auf Standardhardware läuft.
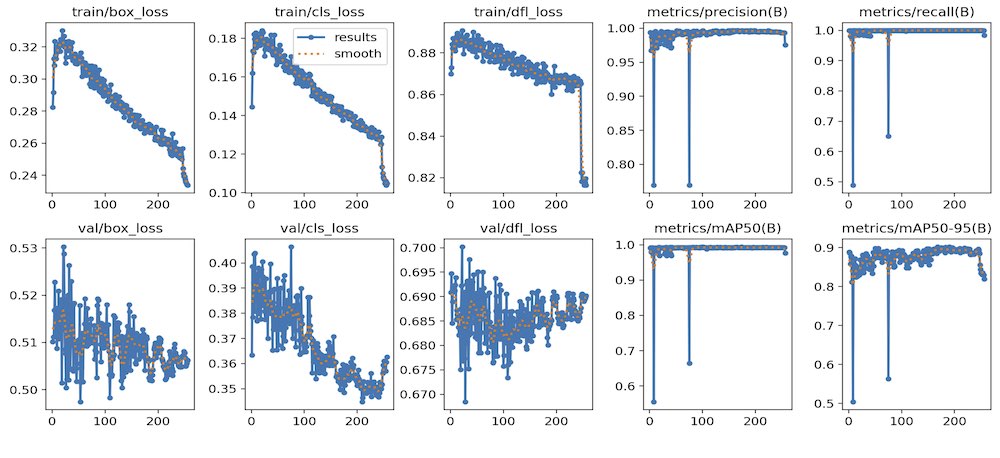
Das trainierte YOLOv8n-Modell erreichte eine hohe Genauigkeit bei allen neun Drohnenkomponenten. Dazu gehörten Bezeichnungen wie Haube grün V1, Haube braun V2, Haube orange V2, Grundplatte weiß V1, Grundplatte blau V2, Grundplatte schwarz V1 und andere visuell unterschiedliche Körper- und Grundplattenvarianten. Wie in Bild 5 dargestellt, nahmen die Trainings- und Validierungsverluste über 256 Epochen hinweg kontinuierlich ab. Das Modell erreichte eine Präzision von 99,6 %, eine Wiedererkennung von nahezu 100 % und mAP@0.5 von 99,2 %, obwohl keine Datenerweiterung verwendet wurde. Während diese Kennzahlen die Fähigkeit des Modells widerspiegeln, Drohnenteile mit hoher Zuverlässigkeit korrekt zu erkennen, ist ein Test in der realen Welt das wichtigste Unterscheidungsmerkmal für die tatsächliche Leistung.
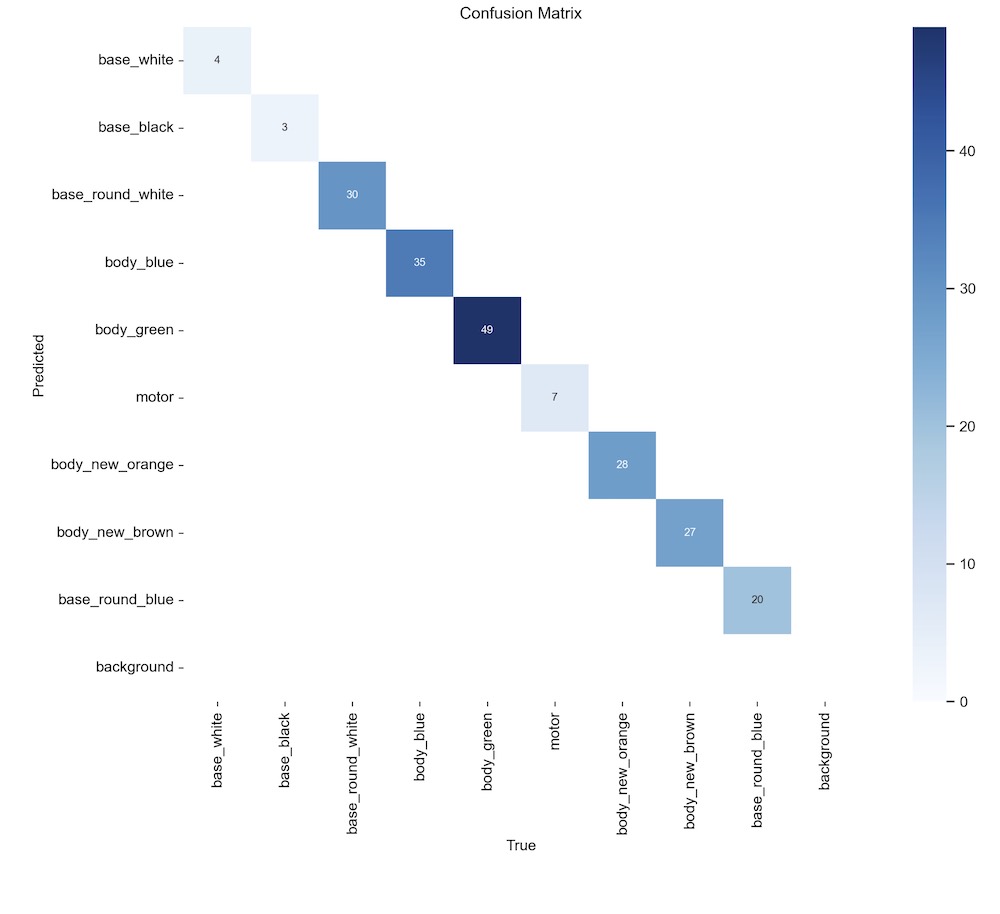
Die Konfusionsmatrix in Bild 6 zeigt genaue Vorhersagen für fast alle Klassen, mit geringer Konfusion sogar zwischen visuell ähnlichen Grundplatten- oder Karosserievarianten. Diese Ergebnisse bestätigen, dass das System eine zuverlässige, kostengünstige Auswahlhilfe unter Verwendung von Consumer-Webcams und minimalen Trainingsdaten unterstützen kann.
Obwohl das System unter kontrollierten Laborbedingungen eine hohe Genauigkeit erreichte, wurden einige Einschränkungen festgestellt. Bei schlechten Lichtverhältnissen erkannte das Modell nicht immer das richtige Teil oder zeigte verzögerte Reaktionen. Alle Trainings- und Validierungsbilder wurden in einer gut beleuchteten Umgebung aufgenommen, was die Verallgemeinerung auf dunklere oder variablere Beleuchtungssituationen einschränken könnte. Diese Ergebnisse deuten darauf hin, dass eine konstante Beleuchtung oder zusätzliche Trainingsdaten unter verschiedenen Bedingungen notwendig wären, um die Robustheit in der Praxis zu gewährleisten. In zukünftigen Iterationen werden Techniken zur Bildverbesserung erforscht, um eine robuste Erkennung zu gewährleisten.
Demonstration einer kosteneffizienten visuellen Verifizierung für die manuelle Kommissionierung
Während herkömmliche Systeme wie Pick-by-Light oder Projektionssysteme Infrastrukturinvestitionen von mehr als 170 000 bis 200 000 US-Dollar für 25 Benutzer erfordern, wurde der Prototyp der Fallstudie mit handelsüblichen Komponenten implementiert: einer 70 Euro teuren Webcam, einem Mittelklasse-Laptop mit einem NVIDIA RTX A1000-Grafikprozessor und Open-Source-Software (YOLO).
Das einzige erforderliche Modelltraining war die Feinabstimmung anhand von ca. 2000 beschrifteten Bildern, eine Aufgabe, die ohne Erweiterungen und unter Verwendung von Standard-Python-Bibliotheken durchgeführt wurde. Es wurden keine kommerziellen Lizenzen benötigt. Nach der Bereitstellung wird die Inferenz vollständig lokal ausgeführt, wodurch Cloudkosten entfallen und der Datenschutz gewährleistet ist. Im Betrieb zeigte das System Latenzzeiten von 100 ms pro Bild und erkannte Drohnenteile mit 99,2 % mAP@0.5. Damit stellt die Lösung eine praktische, barrierearme Alternative für KMU dar, die eine Verifizierung ohne den finanziellen oder technischen Aufwand herkömmlicher Systeme anstreben.
Dieser Prototyp und seine ersten Ergebnisse wurden auf der POMS-Jahreskonferenz 2025 in Atlanta [32] vorgestellt, wo der Ansatz für seine einfache Anwendung und sein Potenzial zur Verbesserung der Genauigkeit in manuellen Arbeitsabläufen gewürdigt wurde. Während der Prototyp die praktische Machbarkeit demonstriert, erkennen wir an, dass eine vollständige Kosten-Nutzen-Analyse und eine systematische Leistungsvalidierung in verschiedenen realen Umgebungen noch ausstehen.
Multimodale Unterstützung: Integration von Seh- und Sprachmodellen
Große Sprachmodelle (Large Language Models, LLMs), die auf Transformer-Architekturen [33] basieren und anhand großer Textdatensätze trainiert werden, sind in der Lage, menschliche Sprache zu verstehen, zu verarbeiten und auch zu erzeugen [34]. Diese Fähigkeiten machen sie auch im industriellen Kontext sehr nützlich.
Zu den Kernfähigkeiten im industriellen Umfeld gehören das Verstehen natürlicher Sprache (Natural Language Understanding, NLU), die Texterzeugung, das Schließen von Schlüssen und das Befolgen von Anweisungen [34-36]. NLU hilft bei der Verarbeitung verschiedener Arten von Texten wie technischen Handbüchern, Bedienerprotokollen oder regulatorischen Dokumenten [34]. Die Textgenerierung ist für die Automatisierung des Schreibens von Berichten oder der Erstellung von Dokumentation unerlässlich [34]. Die Argumentationsfähigkeiten eines LLM in einem industriellen Umfeld sind wichtig für Problemlösungen, strategische Planung und Prozessoptimierung [37].
LLMs können benutzerdefinierten Anweisungen folgen, indem sie diese mit detaillierten Kontextinformationen durch die Verwendung von Retrieval-Augmented Generation (RAG) anreichern [36]. Die Verwendung von RAG ist eine Methode zur Umwandlung von Allzweck-LLMs in industrielle KI-Systeme. Für einen zuverlässigen industriellen Einsatz müssen LLMs als aufgabenspezifische Agenten arbeiten, die kontextbezogenes Wissen nutzen und die Ergebnisse anhand vordefinierter Regeln validieren [38]. Mensch-Maschine-Schnittstellen (HMIs) profitieren ebenfalls von den Fähigkeiten der LLMs. LLMs können komplexe Menüs in HMIs durch eine Chat-Schnittstelle ersetzen, über die der Arbeiter seine Fragen per Text oder Sprachbefehl stellen kann, wodurch die HMIs zugänglicher und intuitiver werden [39, 40].
Aufbauend auf den zuverlässigen Erkennungen und der logikgesteuerten Führung, die von Objekterkennungsmodellen angeboten werden, führt die Integration von LLMs eine neue Ebene der Anpassungsfähigkeit und Kommunikation ein. In dieser multimodalen Umgebung fungiert das Bildverarbeitungsmodell als „Augen“ des Systems, das die physikalische Genauigkeit sicherstellt [41], während das LLM als „Gehirn“ und „Stimme“ des Systems fungiert und Kontext, Schlussfolgerungen und menschenfreundliche Interaktion bietet [37].
Eine Schlüsselfunktion des LLM im Zusammenhang mit der Kommissionierhilfe könnte darin bestehen, den Werker durch schrittweise Anweisungen zu führen, die aus der Auftragskonfiguration generiert werden (z. B. zuerst Teil X, dann Teil Y) und die Vervollständigungsschritte des Arbeiters in Echtzeit zu überwachen. Die Mehrsprachigkeit von LLMs in Verbindung mit Sprachbefehlen ermöglicht eine nahtlose Interaktion mit Arbeitern mit unterschiedlichem Hintergrund. Das LLM kann auch dabei helfen, neue Mitarbeiter mit interaktiven Tutorials zu schulen, es kann den Mitarbeiter im Falle eines Fehlers anleiten und es kann Berichte auf der Grundlage von Bildverarbeitungsprotokollen und der Auftragskonfiguration erstellen [37].
Die meisten dieser LLM-Funktionen sind eng mit den Ergebnissen des Bildverarbeitungsmodells verbunden und umgekehrt, wodurch eine positive Synergie entsteht. Ein beispielhafter Arbeitsablauf für diese Synergie ist die Fehlerrückkopplungsschleife: Das Bildverarbeitungsmodell erkennt einen Fehler im Kommissionierprozess, und anschließend erklärt das LLM dem Mitarbeiter, worin der Fehler besteht und wie er behoben werden kann. Eine weitere Synergie ist die Verfolgung der Montageschritte über die Teileprüfung durch das Bildverarbeitungsmodell und die parallele Generierung von Montageanweisungen für den aktuellen Schritt durch das LLM. Eine Synergie, die zur Fehlervermeidung führt, ist die folgende: Das Bildverarbeitungsmodell erkennt ein häufiges Fehlermuster, woraufhin das LLM den Werker präventiv warnt, um diesen Fehler zu vermeiden [42].
Dieser multimodale Ansatz bringt mehrere Vorteile mit sich. Er reduziert die kognitive Belastung der Arbeiter, indem er sie über Sprachbefehle durch den Prozess führt [43]. Durch die Multimodalität wird das System von der reinen Fehlererkennung zur Fehlervermeidung. Durch die Vermeidung von Fehlern und die Anleitung in Echtzeit beschleunigt der multimodale Kommissionierassistent den Arbeitsablauf bei der Kommissionierung [44].
Bedarf an einem kontextabhängigen, sprachbewussten Echtzeit-Assistenzsystem
Was wäre, wenn der Kommissionierassistent mehr könnte, als nur Teile zu erkennen? Was wäre, wenn er sprechen, Fehler erklären und die Mitarbeiter in ihrer eigenen Sprache durch die einzelnen Schritte führen könnte? Diese Fragen haben uns dazu veranlasst, unser bildverarbeitungsbasiertes System zu einem interaktiven System auszubauen. In diesem Abschnitt untersuchen wir, wie durch die Kombination von Objekterkennung und einem Sprachmodell ein Assistent geschaffen werden kann, der nicht nur sieht, was der Arbeiter tut, sondern auch in Echtzeit mit hilfreichen Rückmeldungen und Anweisungen reagiert.
Fallstudie 1 hat gezeigt, dass kostengünstige Objekterkennungsmodelle wie YOLO mit einfacher Hardware Picksequenzen effektiv in Echtzeit überprüfen können. Die visuelle Überprüfung stellt zwar die Korrektheit sicher, geht aber nicht auf die umfassenderen betrieblichen Herausforderungen ein, mit denen KMU konfrontiert sind, wie z. B. die Einarbeitung neuer oder befristet beschäftigter Mitarbeiter, die Überwindung von Sprachbarrieren und die Bewältigung des Ausscheidens von Mitarbeitern. Herkömmliche Umschulungsmethoden sind zeitaufwändig und bei mehrsprachigen Teams oft ineffektiv.
Gleichzeitig hängen intelligente Assistenzsysteme in der neueren Literatur weitgehend von Cloud-basierten LLMs und infrastrukturlastigen Setups ab [45, 46], die mit ressourcenbeschränkten Umgebungen nicht kompatibel sind. Es besteht weiterhin eine deutliche Diskrepanz zwischen den praktischen Echtzeit-Bedürfnissen in der Kleinserienfertigung und den Annahmen, die in den meisten KI-Werkzeugen enthalten sind. Benötigt wird ein System, das nicht nur eine visuelle Überprüfung bietet, sondern auch eine interaktive, mehrsprachige Unterstützung, die auf die einzelnen Phasen der Aufgabe abgestimmt ist.
Im nächsten Abschnitt stellen wir SOPHIE vor – unseren leichtgewichtigen multimodalen Assistenten, der die lokale YOLO-Erkennung mit einem kontextabhängigen LLM kombiniert. SOPHIE versteht nicht nur den aktuellen Auftrag, sondern kennt auch den Fortschritt des Arbeiters und ermöglicht so dynamische Unterstützung bei Bedarf für jeden einzelnen Schritt, ohne auf Cloud-Dienste angewiesen zu sein.
Die zweite Fallstudie erweitert die erste durch die Integration eines lokalen großen Sprachmodells (LLM) in den Kommissionierworkflow. Es sollte untersucht werden, ob durch die Kombination von Bildverarbeitung und kontextbezogenem Sprachverständnis eine mehrsprachige Benutzerunterstützung in Echtzeit möglich ist, ohne auf eine Cloud-Infrastruktur zurückgreifen zu müssen. Das LLM wurde nicht neu trainiert, sondern arbeitete mit strukturierten Aufforderungen, die aus dem aktuellen Auftrag und Erkennungsstatus abgeleitet wurden. Die Studie konzentrierte sich auf die Erweiterung des Anwendungsbereichs, die Benutzerinteraktion und die Demonstration eines kostengünstigen Einsatzes mit handelsüblicher Hardware.
Fallstudie 2: Ein Experiment zu den Synergien zwischen Vision und Sprache
Um unsere Ideen zur Kombination von Bildverarbeitung und Sprache zu validieren, haben wir einen Anwendungsprototyp (SOPHIE) auf der Grundlage von Fallstudie 1 implementiert, der das für Fallstudie 1 trainierte Bildverarbeitungsmodell mit einem lokalen LLM (WizardLM2) [47] kombiniert. Die Idee von SOPHIE ist, dass das LLM Echtzeit-Anfragen des Benutzers auf der Grundlage der aktuellen Bestellung und des vom YOLO-Modell erkannten Teils beantwortet.
SOPHIE ist als Tkinter [48] Anwendung implementiert, wie in Bild 7 gezeigt, die aus einem Kamerastream mit zusätzlichen Informationen (FPS, verwendete Kamera, Startzeit usw.), einem Schieberegler für die Konfidenzschwelle zur Erkennung von Teilen mit dem YOLO-Modell, einem Vorschaubild und Text für das aktuell erwartete Teil, einer Übersicht über den gesamten Auftrag mit seiner Teilesequenz und einer Schaltfläche zum Öffnen des Chat-Popups mit dem LLM besteht. Im Chat-Popup kann der Benutzer entweder vordefinierte Fragen in Deutsch und Englisch auswählen, die für die Kommissionieraufgabe relevant sind, oder eigene Fragen stellen [48]. Um eine sinnvolle Antwort zu generieren, wird dem LLM eine Aufforderung gegeben, die eine Kombination aus verschiedenen Arten von Kontexten darstellt.
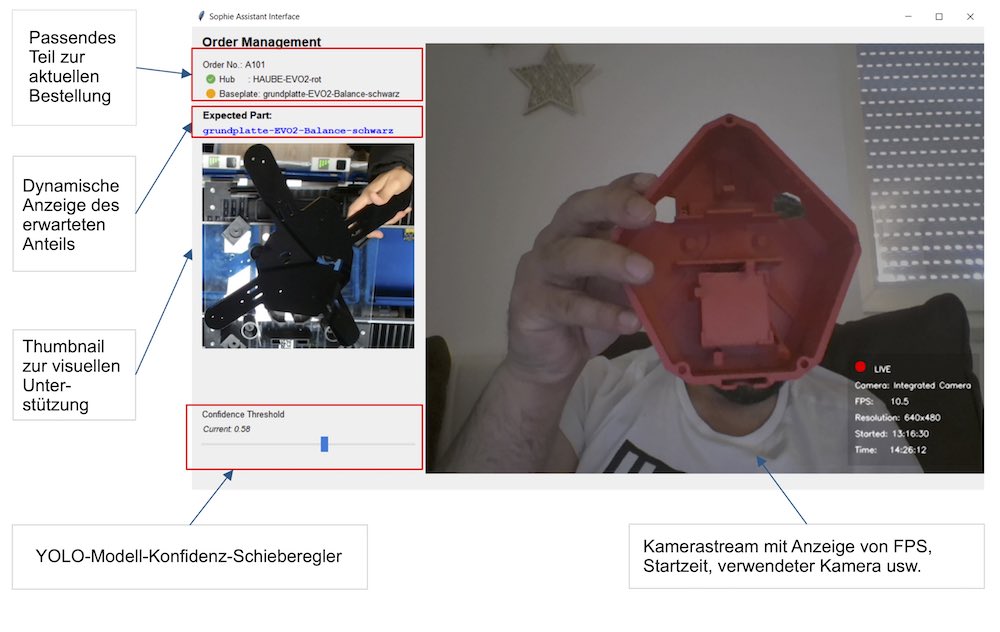
Die Basis des Prompts ist der Systemprompt, der für alle Anfragen immer gleich bleibt und dem LLM seine Aufgabe (mehrsprachiger Assistent für Drohnenmontage) mitteilt, wie er antworten soll (knapp und präzise, sprachbewusst) und dass er den gesamten gegebenen Kontext nutzen soll. Der Kontext beginnt mit Informationen über den Auftrag und seinen Status. Die Auftragsbestätigung besteht aus der Auftragskennung, der erwarteten Nabe und der erwarteten Grundplatte, während der Status dem LLM mitteilt, welche Teile bereits verifiziert sind, welche die nächsten erwarteten Teile sind und ob irgendwelche falschen Erkennungen aufgetreten sind.
Das nächste Kontextsegment in der Eingabeaufforderung besteht aus Anweisungen zur Auswahl der Nabe oder der Grundplatte, je nachdem, welches Teil gerade erwartet wird. Das letzte Kontextelement ist die eigentliche Frage des Benutzers.
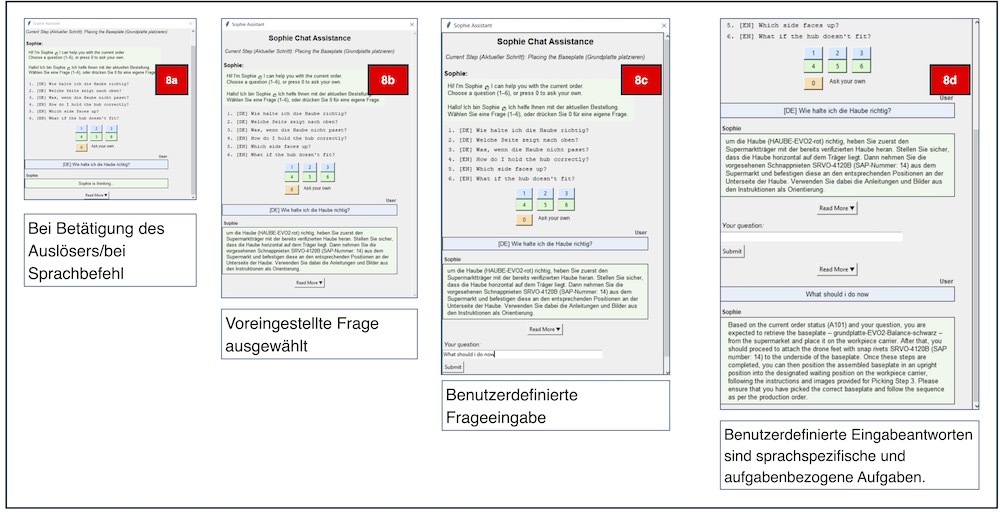
Die von SOPHIE generierten Antworten, wie die in Bild 8, zeigen, dass das System durch die Kombination verschiedener Kontexte in der Eingabeaufforderung den Benutzer durch den Kommissioniervorgang führen und ihm im Falle eines Kommissionierfehlers helfen kann. Die SOPHIE-Schnittstelle demonstriert vier übliche Interaktionsphasen während des Kommissioniervorgangs (Bild 8).
In Bild 8a initiiert der Benutzer eine Hilfestellung per Taste oder simulierter Spracheingabe. Bild 8b zeigt vordefinierte mehrsprachige Fragen; hier wählt der Benutzer eine deutsche Frage aus und erhält eine deutsche Antwort. In Bild 8c wählt der Benutzer die Option 0, um eine benutzerdefinierte Frage manuell einzugeben, dieses Mal in Englisch. Bild 8d zeigt die kontextabhängige Antwort von SOPHIE auf Englisch und unterstreicht damit die Fähigkeit von SOPHIE, einen nahtlosen Sprachwechsel auf der Grundlage von Benutzereingaben durchzuführen.
Erweiterung der Fähigkeiten mit LLM-Unterstützung bei minimalem Overhead
Während die Kombination von NLP und Bildverarbeitung oft als ressourcenintensiv angesehen wird, wurde SOPHIE mit Blick auf Machbarkeit und Zugänglichkeit entwickelt. Die Anwendung wurde vollständig in Python unter Verwendung von Tkinter entwickelt und läuft auf der gleichen Consumer-Hardware wie in Fallstudie 1 (4 GB Nvidia GPU, 32 GB RAM). Bei der Sprachkomponente (WizardLM2) [47] handelt es sich um einen vortrainierten Open-Source-LLM, der lokal ohne Feinabstimmung läuft. Dadurch werden teure Trainingszyklen oder serverbasierte Inferenz vermieden.
Obwohl die LLM-Antwortzeit (~20-30 Sekunden pro Abfrage) langsamer als optimal ist, ist dies ein Kompromiss, der für Offline-Betrieb, Datenschutz und Kostenkontrolle eingegangen wurde. Alle Kernfunktionalitäten wie visuelle Validierung, mehrsprachige Unterstützung und kontextbezogene Aufgabenführung werden ohne zusätzliche Lizenzen oder Cloud-Infrastruktur erreicht. SOPHIE stellt somit eine praktische Erweiterung von bildverarbeitungsbasierten Kommissioniersystemen dar, die interaktive Unterstützung in begrenzten industriellen Umgebungen umfassender und anpassungsfähiger macht.
Während der Prototyp die praktische Machbarkeit demonstriert, erkennen wir an, dass eine vollständige Kosten-Nutzen-Analyse und eine systematische Leistungsvalidierung in verschiedenen realen Umgebungen noch aussteht.
Auf dem Weg zu einer intelligenteren Kommissionierung
Der Vergleich bestehender Assistenzsysteme zeigt einen klaren Kompromiss zwischen Fehlerquoten und Implementierungskosten, der die Zugänglichkeit für viele Unternehmen oft einschränkt. Die erste Fallstudie, die wir durchgeführt haben, hat verdeutlicht, dass eine präzise Überprüfung und Anordnung von Bauteilen durch den Einsatz von Computer-Vision-Technologien und grundlegenden logischen Verfahren realisierbar ist, wobei dies mit erschwinglicher und weit verbreiteter Hardware umgesetzt werden kann.
Gleichzeitig bieten die jüngsten Entwicklungen in der generativen KI, insbesondere Large Language Models, neue Möglichkeiten zur Verbesserung der Interaktion, der Anpassungsfähigkeit und der mehrsprachigen Zugänglichkeit. Unsere zweite Fallstudie zeigt, dass die Kombination von Bildverarbeitung mit Sprachmodellen das Potenzial hat, die Führung des Picker zu verbessern und damit die Fehlerquote zu senken. Zusammen haben diese Technologien das Potenzial, traditionelle Systeme zu ergänzen oder schrittweise zu ersetzen, indem sie skalierbare, intelligente und kostengünstige Alternativen bieten.
Literatur
[1] Grosse, E. H.; Glock, C. H.; Jaber, M. Y.; Neumann, W. P.: Einbindung menschlicher Faktoren in Kommissionierplanungsmodelle: Rahmenbedingungen und Forschungsmöglichkeiten. In: Internationale Zeitschrift für Produktionsforschung 53 (2015) 3, S. 695-717. DOI: https://doi.org/10.1080/00207543.2014.919424 .[2] De Koster, R.; Le-Duc, T.; Roodbergen, K. J.: Gestaltung und Steuerung der Lagerkommissionierung: A literature review. In: European journal of operational research 182 (2007) 2, S. 481-501. DOI: https://doi.org/10.1016/j.ejor.2006.07.009 .
[3] Casella, G.; Volpi, A.; Montanari, R.; Tebaldi, L.; Bottani, E.: Trends in Order Picking: A 2007-2022 review of the literature. In: Production & Manufacturing Research 11 (2023) 1, S. 2191115. DOI: https://doi.org/10.1080/21693277.2023.2191115 .
[4] Łopuszyński, M.; Janusz, K.; Karwat, D.: Vergleichende Studie ausgewählter Kommissioniermethoden: Effizienz, Ergonomie und Anpassungsrate von neuen Mitarbeitern. In: Sensoren 25 (2025) 3, S. 923. DOI: https://doi.org/10.3390/s25030923 .
[5] Li, F.: Vergleich zwischen Pick-by-Vision und Pick-by-Paper: Eine experimentelle Bewertung von Kommissionierzeiten, Fehlerraten und Benutzerzufriedenheit. Hochschule für angewandte Wissenschaften Neu-Ulm 2020. URL: https://publications.hs-neu-ulm.de/1750/1/Kunze_Fang_WP_42_Comparing%20pick%20by%20vision%20to%20pick%20by%20paper.pdf , Zugriff am 14.05.2025.
[6] UNEX: Paper Picking Processes: Are They Picking Your Pocket? URL: https://blog.unex.com/paper-picking-processes , Zugriff am 14.05.2025.
[7] Schriefer, J.: Warum verwendet die Mehrheit der DCs immer noch Papier für die Kommissionierung? URL: https://www.lucasware.com/blog-majority-dcs-still-use-paper-picking/ , Zugriff am 14.05.2025.
[8] auftragsbezogen: Warum die Zettelwirtschaft Ihrem Lager die Taschen vollstopft. URL: https://orderwise.co.uk/en/blog/why-paper-picking-is-picking-the-pockets-of-your-warehouse , abgerufen am 14.05.2025.
[9] Lucchese, A.; Mummolo, G.: Human-Centric Assistive Technologies in Manual Picking and Assembly Tasks: A Literature Review. In: Management and Production Engineering Review 15 (2024) 2, S. 73-86. DOI: https://doi.org/10.24425/mper.2024.151132 .
[10] Mandar, E. M.; Dachry, W.; Bensassi, B.: Toward a Real-Time Picking Errors Prevention System Based on RFID Technology. In: Advances on Smart and Soft Computing (2021), Singapur, S. 303-318. DOI: https://doi.org/10.1007/978-981-15-6048-4_27 .
[11] Amit, J.: Voice Picking Systems: Sind sie die beste Wahl für Ihr Lager? URL: https://aiola.ai/blog/voice-picking-systems , Zugriff am 14.05.2025.
[12] Badwi, M.: Sprachgesteuerte Kommissionierung oder Pick-to-Light: Was ist das Beste für Ihr Unternehmen? URL: https://www.scjunction.com/blog/voice-picking-or-pick-to-light-which-is-best-for-your-business , Zugriff am 14.05.2025.
[13] Gast: 3 Dinge, die man wissen sollte, bevor man in Voice Picking investiert. URL: https://www.allthingssupplychain.com/3-things-to-know-before-investing-in-voice-picking/ , Zugriff am 14.05.2025.
[14] Markowitz, J.: Ergonomie der Stimme. URL: https://www.speechtechmag.com/Articles/Columns/Forward-Thinking/Ergonomics-of-the-Voice-34400.aspx , Zugriff am 14.05.2025.
[15] Stipp, T.: Kommissioniertechnologien im Vergleich. URL: https://www.procatdt.com/wp-content/uploads/2021/01/Comparing-Order-Picking-Technologies.pdf , Zugriff am 14.05.2025.
[16] Yzquierdo, J.: Was ist ein Pick-to-Light-System und wie sieht es mit Voice aus? URL: https://www.lucasware.com/what-is-a-pick-to-light-system-and-how-does-voice-compare/ , Zugriff am 15.05.2025.
[17] Hanrahan, D.: Multimodale Kommissioniertechnologie bietet ROI für kleine bis mittelgroße Auftragsabwicklungsprozesse. URL: https://parcelindustry.com/print-article-1322-permanent.html , Zugriff am 14.05.2025.
[18] Packiyo: Pick to Light System erklärt: All you need to know. URL: https://www.packiyo.com/blog/pick-to-light , Zugriff am 14.05.2025.
[19] Ames, B.: Smartglasses bekommen einen zweiten Blick von Lagerhäusern. URL: https://www.dcvelocity.com/articles/28603-smartglasses-get-a-second-look-from-warehouses , Zugriff am 14.05.2025.
[20] Schriefer, J.: The reality of smart glasses for warehouse vision picking. URL: https://www.lucasware.com/warehouse-vision-picking/ , Zugriff am 28.03.2025.
[21] Heuts, P.: DHL experimentiert mit Augmented Reality. 2017. URL: https://www.etui.org/sites/default/files/Hesamag_16_EN-22-26.pdf , Zugriff am 28.03.2025.
[22] Herzog, N. V.; Beharic, A.: Auswirkungen der Nutzung von Smart Glasses auf das Sehvermögen. In: Human Systems Engineering and Design II: Proceedings of the 2nd International Conference on Human Systems Engineering and Design (IHSED2019): Future Trends and Applications, September 16-18, 2019, Universität der Bundeswehr München, München, Deutschland (2020), S. 808-812. DOI: https://doi.org/10.1007/978-3-030-27928-8_123 .
[23] Lai, K.-h.; Cheng, T. E.: Just-in-time logistics. London 2016.
[24] Khanam, R.; Hussain, M.; Hill, R.; Allen, P.: A comprehensive review of convolutional neural networks for defect detection in industrial applications. In: IEEE Access 12 (2024) S. 94250 – 94295. DOI: https://doi.org/10.1109/ACCESS.2024.3425166 .
[25] Vijayakumar, A.; Vairavasundaram, S.: Yolo-based object detection models: A review and its applications. In: Multimedia Tools and Applications 83 (2024) 35, S. 83535-83574. DOI: https://doi.org/10.1007/s11042-024-18872-y .
[26] Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J.: Object detection in 20 years: A survey. In: Proceedings of the IEEE 111 (2023) 3, S. 257-276. DOI: https://doi.org/10.48550/arXiv.1905.05055 .
[27] Ahmad, H. M.; Rahimi, A.: Deep Learning-Methoden zur Objekterkennung in der intelligenten Fertigung: A survey. In: Journal of Manufacturing Systems 64 (2022) S. 181-196. DOI: https://doi.org/10.1016/j.jmsy.2022.06.011 .
[28] Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A.: You Only Look Once: Unified, Real-Time Object Detection. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016), S. 779-788. DOI: https://doi.org/10.1109/CVPR.2016.91 .
[29] Sekar, K.; Dheepa, T.; Sheethal, R.; Suvarna Smita, R.; Teja, V. D.: Efficient Object Detection on Low-Resource Devices Using Lightweight MobileNet-SSD. In: 2025 International Conference on Intelligent Systems and Computational Networks (ICISCN) (2025), Bangalore, S. 1-6. DOI: https://doi.org/10.1109/ICISCN64258.2025.10934442 .
[30] Tan, M.; Pang, R.; Le, Q. V.: Efficientdet: Skalierbare und effiziente Objekterkennung. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2020), S. 10781-10790. DOI: https://doi.org/10.1109/CVPR42600.2020.01079 .
[31] Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.et al.: Detrs beat yolos on real-time object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2024), S. 16965-16974. DOI: https://doi.org/10.48550/arXiv.2304.08069 .
[32] Siddiqui, M. K.; Hoffman, B.; Grinninger, J.: Real-Time Object Detection using AI for Enhanced Operational Efficiency. Präsentiert auf der POMS-Jahreskonferenz 2025, Atlanta, 8. bis 12. Mai.
[33] Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.et al.: Attention is all you need. In: Advances in neural information processing systems 30 (2017) S.
[34] Zhao, W. X.; Zhou, K.; Li, J.; Tang, T.; Wang, X. et al.: A survey of large language models. In: Journal (2023). DOI: https://doi.org/10.48550/arXiv.2303.18223 .
[35] Wasti, S. M.; Pu, K. Q.; Neshati, A.: Large Language User Interfaces: Voice Interactive User Interfaces powered by LLMs. In: Intelligent Systems Conference (2024), S. 639-655. DOI: https://doi.org/
[36] Xia, Y.; Jazdi, N.; Weyrich, M.: Applying Large Language Models for intelligent industrial automation. In: atp magazin 66 (2024) 6-7, S. 62-71. DOI: https://doi.org/10.17560/atp.v66i6-7.2739 .
[37] Li, Y.; Zhao, H.; Jiang, H.; Pan, Y.; Liu, Z.et al.: Große Sprachmodelle für die Fertigung. In: Journal (2024). DOI: https://doi.org/10.48550/arXiv.2410.21418.
[38] Halse, G.: Beyond the Prompt: Harnessing Industrial AI Agents for Reliable Automation. URL: https://www.gavinhalse.com/ai-in-manufacturing/beyond-the-prompt-harnessing-industrial-ai-agents-for-reliable-automation/ , Zugriff am 15.05.2025.
[39] Shone, O.: 5 Schlüsselmerkmale und Vorteile von großen Sprachmodellen. URL: https://www.microsoft.com/en-us/microsoft-cloud/blog/2024/10/09/5-key-features-and-benefits-of-large-language-models/ , Zugriff am 14.05.2025.
[40] Kaur, J.: Enhancing Manufacturing with Large Language Models (LLMs). URL: https://www.xenonstack.com/blog/large-language-model-manufacturing , Zugriff am 15.05.2025.
[41] Admon, W.: Intelligent Humanoid Robots: An Overview and Focus on Visual Perception Systems. URL: https://www.basic.ai/blog-post/intelligent-humanoid-robots-vision-perception , Zugriff am 15.05.2025.
[42] Mikołajewska, E.; Mikołajewski, D.; Mikołajczyk, T.; Paczkowski, T.: Generative AI in AI-Based Digital Twins for Fault Diagnosis for Predictive Maintenance in Industry 4.0/5.0. In: Angewandte Wissenschaften 15 (2025) 6, S. 3166. DOI: https://doi.org/10.3390/app15063166.
[43] Gkintoni, E.; Antonopoulou, H.; Sortwell, A.; Halkiopoulos, C.: Challenging Cognitive Load Theory: The Role of Educational Neuroscience and Artificial Intelligence in Redefining Learning Efficacy. In: Brain Sciences 15 (2025) 2, S. 203. DOI: https://doi.org/10.3390/brainsci15020203.
[44] Peiu, B.: Transforming quality control: How AI-powered visual anomaly detection reduces production defects. URL: https://www.craftworks.ai/insights/know-how/transforming-quality-control-how-ai-powered-visual-anomaly-detection-reduces-production-defects/ , Zugriff am 15.05.2025.
[45] Wang, H.; Li, C.; Li, Y.-F.; Tsung, F.: An Intelligent Industrial Visual Monitoring and Maintenance Framework Empowered by Large-Scale Visual and Language Models. In: IEEE Transactions on Industrial Cyber-Physical Systems (2024) S.
[46] Giacalone, E., AI-Powered Autonomous Industrial Monitoring: Integrating Robotics, Computer Vision, and Generative AI. 2025, Politecnico di Torino.
[47] ollama.com: wizardlm2. URL: https://ollama.com/library/wizardlm2 , abgerufen am 26.06.2025.
[48] Love, D.: Tkinter GUI Programming by Example: Lernen Sie, moderne GUIs mit Tkinter zu erstellen, indem Sie reale Projekte in Python erstellen. 2018.
Ihre Downloads
Lösungen: Logistik Logistik, Technologien






