


Potentials, Premises, Perspectives |
Using LLMs to reinterpret corporate knowledge management
| Journal | Industry 4.0 Science |
| Issue | Volume 41, Edition 6, Pages 48-56 |
| Open Access | https://doi.org/10.30844/I4SE.25.6.48 |
| Bibliography | Share | Cite | Download |
Abstract
Article
German industry is facing profound change due to a rapidly aging population. Studies predict that by 2036, around 19.5 million of the current 45.6 million employed people in Germany will retire [1, 2]. That not only aggravates the already prevailing shortage of skilled labor, but also provokes a loss of experience-based knowledge.
As a result, companies in the manufacturing sector are increasingly confronted with the challenge of preserving the knowledge of seasoned employees. Particularly critical in this context is the loss of tacit knowledge—knowledge that is not documented and yet essential for operational excellence. The rapid development of generative artificial intelligence, especially large language models (LLMs), opens up new avenues for systematically capturing, accessing, and efficiently utilizing such knowledge [3]. This study aims to develop an initial concept for a practice-oriented, LLM-based knowledge management system that specifically addresses and evaluates the preservation of tacit knowledge.
Tacit and explicit knowledge
According to Ackoff’s knowledge pyramid (1989), knowledge represents the highest level of abstraction above data and information [4]. Knowledge is considered particularly critical when it is tacit [4]. Alavi and Leidner (2001) define tacit knowledge as skills that are difficult to communicate and deeply embedded in individual routines and thought patterns [5]. In English-language literature, tacit knowledge is distinguished between “tribal,” “tacit,” and “implicit knowledge” [6].
A comprehensible differentiation between the terms is elaborated in [6]. “Tribal knowledge” describes the practical knowledge of (long-standing) employees that is necessary for internal processes. The knowledge acquired by experts through practical, real-world experience (“best practices”) is “tacit knowledge.” And “implicit knowledge” includes cultural knowledge such as traditions and values. Since the study focuses on preserving the experiential knowledge of production employees, tacit knowledge is considered in the sense of “tacit knowledge” and “tribal knowledge.”
Explicit knowledge, for example, work instructions or technical documentation, can be stored and transferred more easily [7]. However, even explicit knowledge frequently loses its applicability and usefulness without the context of tacit reference [8]. Therefore, the preservation and transfer of tacit knowledge are particularly critical.
The challenges of technological knowledge management in industry can be divided into three key barriers: social, technical, and organizational factors [3, 9]. At the social level, for example, a lack of motivation, low recognition for knowledge transfer, or fear of losing significance may disincentivize knowledge sharing. At the technical level, there is often a lack of user-friendly, accessible systems for documenting and retrieving knowledge. At the organizational level, industrial practice often lacks strategic anchoring, formal processes, and internal responsibilities for knowledge retention [3, 10, 11]. This initial study aims to examine the use of LLMs as a tool for collecting tacit knowledge as a possible solution to these technical and organizational challenges.
Elicitation of tacit knowledge
This paper focuses on the elicitation of tacit knowledge. In [12], various methods of knowledge elicitation are collected and compared using a literature analysis. When selecting methods, it is assumed that a combination of different methods is usually needed to capture knowledge holistically. By combining different methods, the weaknesses of individual methods can be compensated [12, 13]. Unstructured and semi-structured interviews in combination with observation are identified as particularly suitable for eliciting tacit knowledge [12]. Interviews are the most commonly method for knowledge elicitation [13]. Observation can be used to capture knowledge that cannot be expressed or is difficult to communicate verbally [12, 13]. Interviews are chosen as the method of knowledge elicitation for this study.
According to Shadbolt et al. [13], interviews can be divided into structured, semi-structured, and unstructured interviews. Unstructured interviews have no fixed sequence and no thematic boundaries. This form of interview provides an overview of the topic and the interviewee can co-determine the focus of the conversation. In contrast, structured interviews follow a fixed structure and use predetermined questions, e.g., “Could you tell me about a typical case?” or “Why would you do that?”. This structure facilitates the subsequent evaluation of the interview and ensures that only thematically important issues are discussed, thus increasing efficiency. One disadvantage of the fixed structure is that topics may be overlooked, especially when conducting an initial overview. [13]
LLMs as a tool for knowledge elicitation
Current technological advances in generative artificial intelligence, particularly LLMs, promise a profound transformation of operational knowledge management [14]. LLMs such as OpenAI, Inc.‘s GPT are based on huge training datasets and can understand and generate human-like language [15, 16]. This opens up new means of capturing, structuring, and contextualizing knowledge [17, 18]. Such systems enable low-threshold collection of experiential knowledge—e.g., via voice-to-text applications.
Despite technological advances, challenges remain in implementing LLMs for preserving tacit knowledge in an industrial context. These include, among others:
- a lack of validation mechanisms, as LLMs do not have inherent logic checking [17]
- data protection and security issues when integrating company-specific content [19]
- acceptance problems at employee level due to skepticism or technical overload [20]
- unclear responsibilities for maintaining and using the knowledge base [16]
For the successful use of LLMs to collect tacit knowledge, it is vital to design these systems so that they not only function flawlessly in technological terms, but are also easy to use and designed with the user in mind [3].
During this study, the reliability and quality of knowledge elicitation will be assessed in advance using an LLM as an example. The research question of the extent to which LLMs can support the above-mentioned technical and organizational challenges will therefore be answered. The study does not yet explicitly include verification with other knowledge sources or a discussion of the necessary technical and social framework conditions, such as data security.
Related study
Van den Bent et al. [21] also investigates whether LLMs are suitable for knowledge elicitation. In the study, the knowledge elicitation process consists of an unstructured interview and subsequent ontology creation. An ontology is a method for conceptualizing knowledge and consists of classes, relations, rules, and instances [22]. The duration of the interview and the behavior of the LLM during the interview, as well as the results of ontology creation, are compared with human experts’ results. The study concludes that interviews using OpenAI’s LLM GPT-4 are more structured than interviews conducted by real people and therefore can yield efficiency gains.
However, the study identifies poorer results in terms of ontology creation. For example, it was found that during ontology creation, the LLM supplements information that is not mentioned in the interviews. Some of this information is factually correct and therefore presumably originates from the LLM’s training data [21]. The present study uses a different methodology than that of van den Bent et al. [21].
Knowledge elicitation through interviews and summarization
During this initial study, a personalized chatbot was developed using OpenAI’s ChatGPT-5 (released in August 2025) that can conduct interviews on any topic with real people. A more recent LLM from the same provider as the related study described above is used.
The aim of the interviews is to gather tacit knowledge from the interviewee. The interviewees should be able to steer the interview thematically but without deviating from the topic and answer specific questions for further clarification. For this reason, semi-structured interviews are chosen for the study. In contrast to the related study, in which an ontology is created, the results of the interview in this study are output in a structured text file after the interview. This summary could then be integrated as a document straight into a knowledge database.
When creating the chatbot, the rules of prompt engineering and the procedure for semi-structured interviews are considered. For this purpose, the role, goal, background information, procedure, and response format are specified. In-depth questions are also integrated into the system prompt as examples. To optimize the system prompt and thus the interview behavior, 15 interviews are conducted, and the system prompt is adjusted after each interview using another chatbot (based on ChatGPT-5). For this purpose, the interviews are reviewed in terms of conversation management and summarization, and if the behavior is inadequate, the correct procedure is specified in more detail in the system prompt.
For the evaluation, three experts are interviewed about nine different topics within the area of production-related innovations and processes. The experts, who are all engineers and experienced with LLMs and production, select the topics. The interview begins with the expert naming the topic, which is then explored in greater detail using questions that the chatbot has tailored to the topic. In contrast, the related study only includes one expert and one topic area. As with [21], a distinction should be made between the evaluation of the interview and the final result, i.e., the summary. The evaluation criteria, including explanations, are shown in Figure 1.
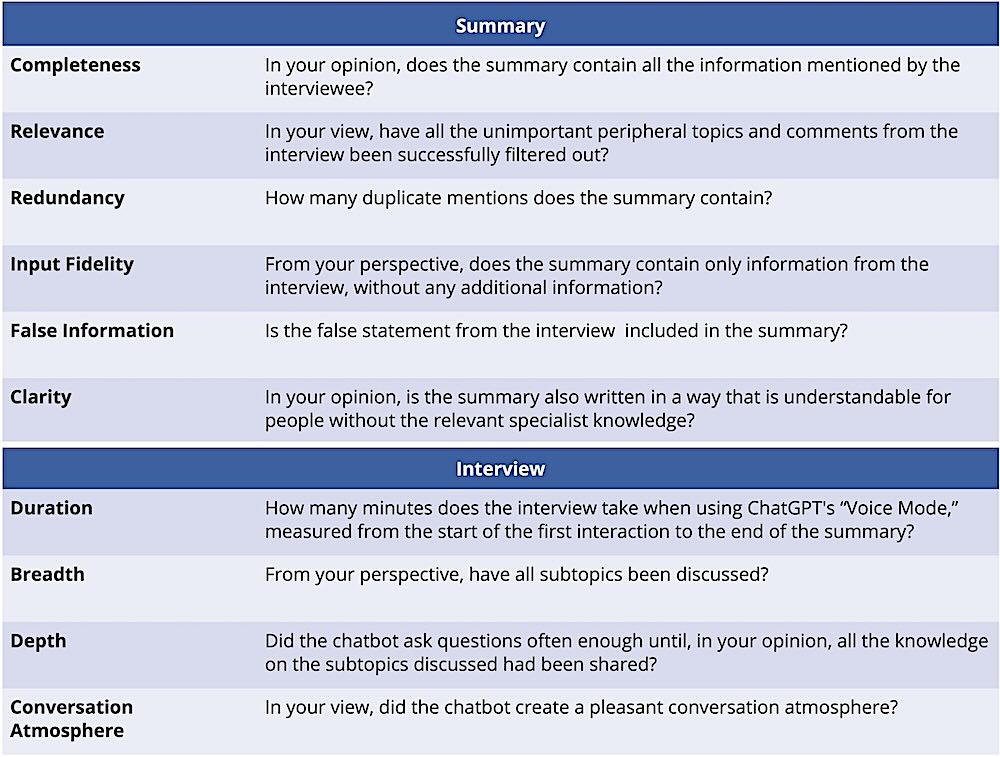
To ensure that the duration of the interviews is comparable, all experts use ChatGPT’s “Voice Mode.”
In the study [21], it was noticed that all ontologies created by the LLM contain hallucinated information. The criterion of input fidelity is intended to verify this finding. Information in the summary that does not originate from the interview is considered a negative rating for input fidelity. The criterion of misinformation is introduced as an extension. For this purpose, the interviewee deliberately make a false statement in each interview. The chatbot aims to collect tacit knowledge without verification from other sources of knowledge, so that false statements should also be included. The reason for this is to potentially uncover new ideas and concepts by individual employees that are described in existing sources of knowledge using a different approach.
After their own interview, each expert evaluates it and the summary based on the criteria described. The experts then assess the clarity of the other candidates’ summaries. The conversation atmosphere is evaluated by the expert after all their own interviews. The criteria of breadth, depth, atmosphere of the conversation, completeness, relevance, input fidelity, and clarity are evaluated subjectively, i.e., the expert chooses between “fully applies,” “rather applies,” “rather does not apply,” and “does not apply at all.” For duration, the time is measured; for redundancy, the number of duplicate entries is counted; and for misinformation, it is checked whether the false statement is included in the summary.
An interview achieves better results than a summary
The results of the study are shown in Figure 2, and the average values of all criteria with the same rating (one to four) are shown in a bar chart in Figure 3 for clear comparison.
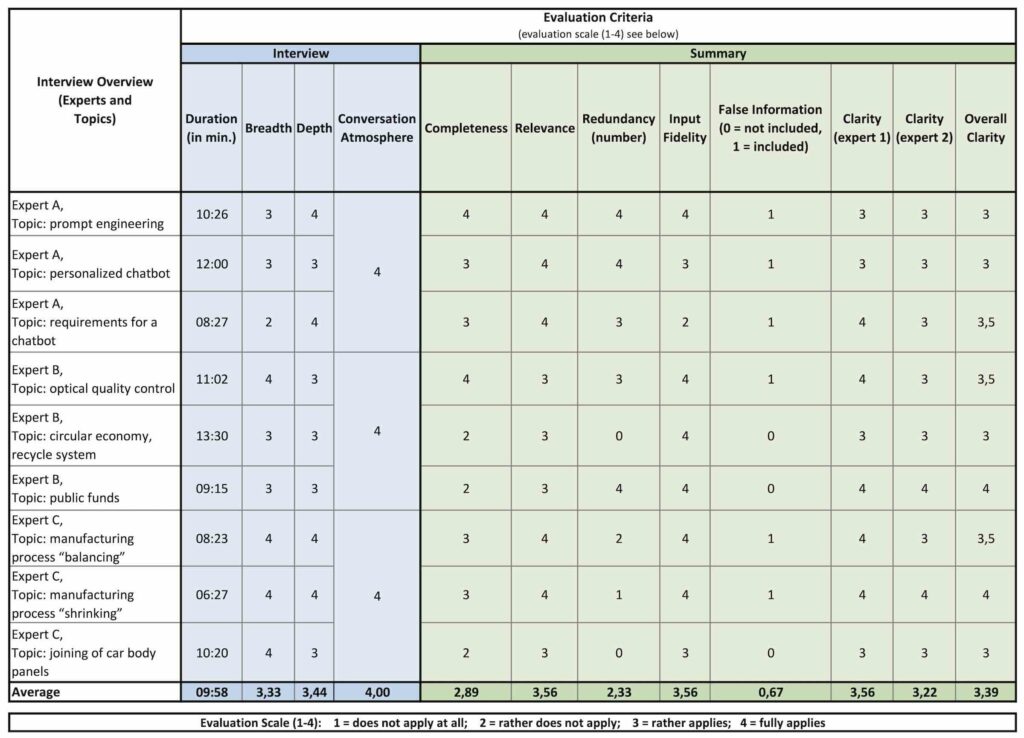
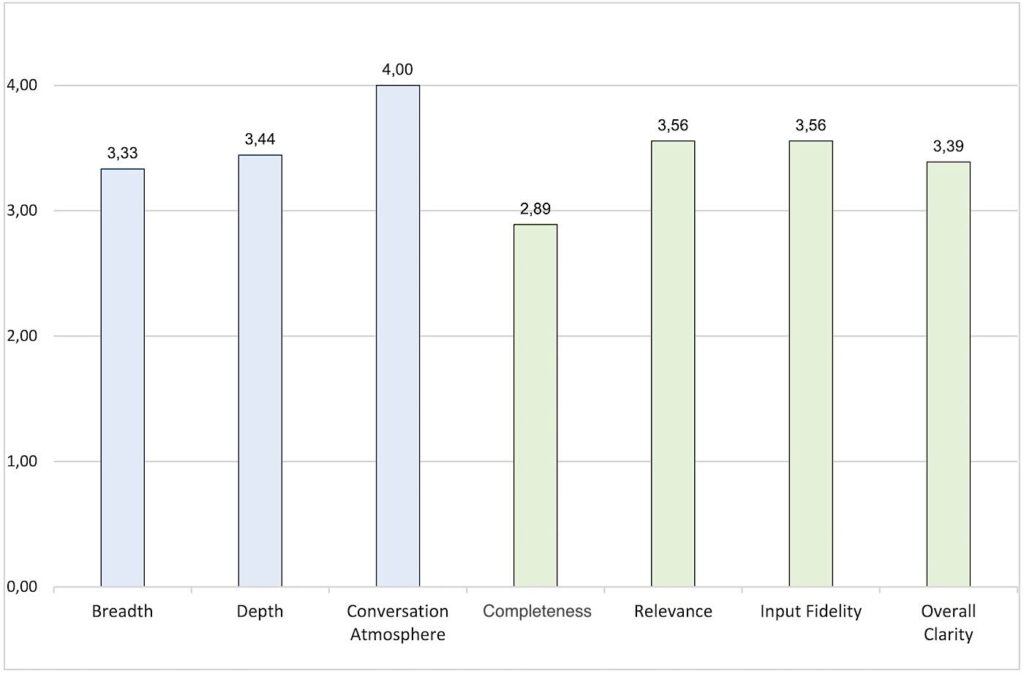
The results of the study show that LLMs have plenty of potential when it comes to interviews. It’s worth noting that the chatbot is better at asking in-depth questions than broad ones. Interviews last about ten minutes on average, so they don’t take up too much time. The atmosphere surrounding, the conversation also scores well. This helps counteract the employee acceptance issues mentioned above.
The values are more volatile in the summary. Completeness, in particular, only scores 2.89 points. As a result, some information from the interview is not included in the summary. Since the goal of the chatbot is to gather implicit knowledge, a complete summary is essential. The other criteria for the summary achieve better results. The LLM seems to be able to filter out unimportant information to a large extent (relevance), and the summary is formulated in a way that is easy to understand—even for people who do not have the expert knowledge (clarity).
However, as it is being incomplete, the result should be viewed in a more nuanced way. The summary contains hardly any irrelevant information, but some important information is also missing. Accordingly, it can be concluded that the chatbot is most likely unable to reliably distinguish between relevant and irrelevant information. On average, each summary contains 2.33 duplicate pieces of information (redundancy). However, total elimination of duplicate information is desirable.
Compared to the results from [21], the results for input fidelity and misinformation are more positive. One possible explanation for the improvement may lie in the use of a more advanced model and the different way in which results were output and presented. This, in turn, suggests that a summary constitutes a more suitable representation for collecting implicit knowledge with an LLM than an ontology. In most summaries, the LLM uses only information from the interview, and even factually incorrect information is included in six out of nine interviews.
Potentials and premises
This study was conducted approximately six weeks after the release of the ChatGPT-5 model. The interviewees described the conversation atmosphere as pleasant. In the evaluation, as the focus in creating the chatbot was on optimizing its interview behavior, the interview performed better than the summary. This result can be improved by increasing the number of preliminary interviews to optimize the system prompt. Moreover, the better performance regarding input fidelity and misinformation compared to the hallucination in the related study is also noteworthy. However, as mentioned in the previous chapter, these results should not be seen as universal. Especially in practical applications, the results for completeness in particular show potential for optimization.
Nevertheless, as this initial study demonstrates, LLMs, and ChatGPT-5 in particular, have great potential in the field of tacit knowledge elicitation. One approach may be the use of a human expert to check for consistency in the summarization process. This would also address the challenge mentioned at the outset, namely that LLMs lack an inherent logic check.
Perspectives for further research
This study provides research institutions with a starting point for further investigation into the subject and encourages companies to consider using LLMs when capturing implicit knowledge. In the future, we plan to conduct numerous additional interviews with external experts and to perform technology benchmarking with other LLMs. Interviews with experts who are not adept at using LLMs can help obtain more nuanced results. The results of our preliminary study fundamentally support a more advanced and programmatically more sophisticated prototype for preserving tacit knowledge in the production environment.
This prototype will be tested, validated, and specifically optimized in various manufacturing companies while focusing on improving the interview output, i.e., the summary. Its aim is to preserve knowledge that would otherwise be lost due to demographic change and, at the same time, to strengthen the manufacturing industry’s competitiveness in the long term. Besides being verified against other sources of knowledge, further studies will examine critical considerations such as data security and ethical issues. This initial study is limited to the technical and organizational challenges of capturing tacit knowledge.
Note from the authors to interested readers: As described, we are aiming to expand the database and conduct further interviews with external experts. If you are interested in the solution we have developed or would like to participate in further studies, we cordially invite you to contact us.
The original German version of this article can be accessed via DOI: 10.30844/I4SD.25.6.48
Bibliography
[1] Deschermeier, P.; Schäfer, H.: The baby boomers are retiring. IW Short Report, No. 78, 2024. URL: https://www.iwkoeln.de/studien/philipp-deschermeier-holger-schaefer-die-babyboomer-gehen-in-rente.html, accessed on July 14, 2025.[2] Federal Statistical Office (Destatis): Press release No. 077 of February 28, 2025: Employment fell slightly in January 2025, 2025. URL: https://www.destatis.de/DE/Presse/Pressemitteilungen/2025/02/PD25_077_132.html, accessed on July 14, 2025.
[3] Finkel P.; Wurster P.: Unlocking Tacit Knowledge in Industrial Production: Exploring Barriers, Practices, and LLM-Driven Potentials for Knowledge Management [Just Accepted]. In: Proceed. of the 59th Hawaii Int. Conf. on Sys. Sc. (HICSS) (2026).
[4] Ackoff., R. L.: From Data to Wisdom. In: Journal of Applied Systems Analysis (1989) 16, pp. 3–9.
[5] Alavi, M.; Leidner, D. E.: Review: knowledge management and knowledge management systems: conceptual foundations and research issues. In: MIS Quarterly 25 (2001) 1, pp. 107–36. DOI: https://doi.org/10.2307/3250961.
[6] Fenoglio, E.; Kazim, E.; Latapie, H.; Koshiyama, A.:(2022). Tacit knowledge elicitation process for industry 4.0. In: Discover Artificial Intelligence (2022), 2(1), 6.
[7] Schiedermair, I.; Kick, E.; Baumgartner, M.; Kopp, T.; Kinkel, S.: Knowledge management in SMEs: Criteria for identifying key internal personnel. In: Journal of Economic Factory Operation 118 (2023) 6, pp. 395–399. DOI: https://doi.org/10.1515/zwf-2023-1087.
[8] Rowley, J.: The wisdom hierarchy: representations of the DIKW hierarchy. In: Journal of Information Science 33 (2007) 2, pp. 163–180. DOI: https://doi.org/10.1177/0165551506070706.
[9] Bostrom, R. P.; Heinen, J. S.: MIS problems and failures: a socio-technical perspective. In: MIS Quarterly 1 (1977) 3, pp. 17–32.
[10] Rülicke, S.: Process-integrated knowledge management – a solution to demographic change. In: Mehlich, P.; Brandenburg, T.; Thielsch, M. (ed): Business Psychology in Practice – Topics and Case Studies for Study and Application. Münster 2014, pp. 249–263.
[11] Sumbal, M. S.; Tsui, E.; Durst, S.; Shujahat, M.; Irfan, I.; Ali, S. M.: A framework to retain the knowledge of departing knowledge workers in the manufacturing industry. In: VINE Journal of Information and Knowledge Management Systems 50 (2020) 4, pp. 631–651.
[12] Hoerner, L.; Schamberger, M.; Bodendorf, F.: Using tacit expert knowledge to support shop-floor operators through a knowledge-based assistance system. In: Computer Supported Cooperative Work (CSCW) 32 (2023) 1, pp. 55–91.
[13] Shadbolt, N. R.; Smart, P. R.; Wilson, J.; Sharples, S.: Knowledge elicitation. In: Evaluation of human work (2015), pp. 163–200.
[14] Finkel, P.; Wurster, P.: Analysis of the Current State and Best Practices of Knowledge Management Applications in the Manufacturing Industry [Just Accepted]. In: Proceed. of the 19th International Conference Interdisciplinarity in Engineering (2026).
[15] Schönfeld, D.: Application examples for AI in industrial service. In: Altenfelder, K.; Kieffer-Radwan, S.; Schönfeld, D. (ed): Services Management and Artificial Intelligence. Wiesbaden 2025. DOI: https://doi.org/10.1007/978-3-658-46665-7_2.
[16] Zur Heiden, P.; Kaltenpoth, S.: Knowledge management for maintenance and repair in distribution networks – Design of an assistance system based on a large language model. In: HMD Praxis der Wirtschaftsinformatik 61 (2024), pp. 911–926. DOI: https://doi.org/10.1365/s40702-024-01074-3.
[17] Storey, V. C.: Knowledge Management in a World of Generative AI: Impact and Implications [Just Accepted]. In: ACM Transactions on Management Information Systems (2025). DOI: https://doi.org/10.1145/3719209.
[18] O’Leary, D. E.: Large Language Models and the Rebirth of Enterprise Knowledge Management. In: IEEE Computer 57 (2024) 9, pp. 20–24.
[19] Hadi, M. U.; Tashi, Q. A.; Qureshi, R.; Shah, A.; Muneer, A.; Irfan, M.; Zafar, A.; Shaikh, M. B.; Akhtar, N.; Wu, J.; Mirjalili, S.: Large Language Models: A Comprehensive Survey of its Applications, Challenges, Limitations, and Future Prospects (2023).
[20] Balzer, V.: Strategic Planning of Production Competencies. University of Stuttgart 2024. http://dx.doi.org/10.18419/opus-15010.
[21] Van den Bent, S.; Pernisch, R.; Schlobach, S.: Investigating Knowledge Elicitation Automation with Large Language Models [Under Review]. In: Semantic Web Journal (2025).
[22] Dengel, A.: Knowledge Representation. In: Semantic Technologies. Heidelberg 2012, pp. 21–72.
Your downloads
Potentials: Training
Solutions: Process Management Quality Management





