


Potenziale, Prämissen, Perspektiven |
Wie sich betriebliches Wissensmanagement dank LLMs neu interpretieren lässt
| Zeitschrift | Industry 4.0 Science |
| Ausgabe | 41. Jahrgang, 2025, Ausgabe 6, Seite 48-56 |
| Open Access | https://doi.org/10.30844/I4SD.25.6.48 |
| Literatur | Teilen | Zitieren | Download |
Abstract
Keywords
Artikel
Die deutsche Industrie steht durch den demografischen Wandel vor einem tiefgreifenden Umbruch. Studien prognostizieren, dass bis 2036 etwa 19,5 Mio. der aktuellen 45,6 Mio. Erwerbstätigen mit Wohnsitz in Deutschland in den Ruhestand treten werden [1, 2]. Dies verstärkt nicht nur den bereits vorherrschenden Arbeits- bzw. Fachkräftemangel, sondern führt insbesondere zu einem Verlust an erfahrungsbasiertem Wissen. Damit stehen Unternehmen im produzierenden Gewerbe vor der Herausforderung, das Wissen ihrer erfahrenen Mitarbeitenden zu konservieren.
Besonders kritisch erscheint in diesem Kontext der Verlust von implizitem Wissen, das nicht dokumentiert, aber essenziell für operative Exzellenz ist. Die rasante Entwicklung generativer Künstlicher Intelligenz, insbesondere großer Sprachmodelle, sogenannter Large Language Models (LLMs), eröffnet neue Potenziale, um dieses Wissen systematisch zu erfassen, zugänglich zu machen und effizient zu nutzen [3]. Diese Studie zielt darauf ab, ein erstes Konzept für ein praxisorientiertes, LLM-basiertes Wissensmanagementsystem zu entwickeln, das gezielt die Konservierung impliziten Wissens adressiert und evaluiert.
Implizites und explizites Wissen
Gemäß Wissenspyramide nach Ackoff (1989) bildet Wissen die höchste Abstraktionsebene über Daten und Information [4]. Dabei wird Wissen insbesondere dann als kritisch angesehen, wenn es implizit ist. [4]. Alavi und Leidner (2001) definieren implizites Wissen als schwer kommunizierbare Fähigkeiten, die tief in individuellen Routinen und Denkmodellen verankert sind [5]. In der englischsprachigen Literatur wird implizites Wissen zwischen „tribal“, „tacit“ und „implicit knowledge“ unterschieden [6].
Eine nachvollziehbare Differenzierung zwischen den Begriffen wird in [6] herausgearbeitet. „Tribal knowledge“, wörtlich übersetzt „Stammeswissen“ beschreibt das praxisbezogene Wissen von (langjährigen) Mitarbeitern, das für interne Prozesse unbedingt benötigt wird. Das Wissen, das durch Experten bei der praktischen Arbeit erlernt wird („best practices“), ist „tacit knowledge“. Und „implicit knowledge“ beinhaltet kulturelles Wissen wie Traditionen und Werte. Da sich die Studie auf die Konservierung des Erfahrungswissens von Produktionsmitarbeitenden fokussiert, wird implizites Wissen im Sinne von „tacit knowledge“ und „tribal knowledge“ betrachtet.
Explizites Wissen – etwa in Form von Arbeitsanweisungen oder technischen Dokumentationen – kann dagegen einfacher gespeichert und übertragen werden [7]. Doch selbst explizites Wissen verliert ohne den Kontext des impliziten Bezugs häufig an Anwendbarkeit und Nutzen [8]. Daher sind die Konservierung und Übertragung impliziten Wissens besonders bedeutsam.
Die Herausforderungen beim technologischen Management von Wissen in der Industrie lassen sich in drei zentrale Barrieren einteilen: soziale, technische und organisationale Faktoren [3, 9]. Auf sozialer Ebene erschweren z. B. fehlende Motivation, geringe Anerkennung für Wissensweitergabe oder die Angst vor Bedeutungsverlust das Teilen von Wissen. Technisch fehlen oft benutzerfreundliche, zugängliche Systeme zur Dokumentation und zum Abruf von Wissen. Organisatorisch kann in der industriellen Praxis oftmals ein Mangel an strategischer Verankerung, formellen Prozessen und internen Zuständigkeiten für Wissenssicherung festgestellt werden [3, 10, 11]. Diese initiale Studie soll den Einsatz von LLMs als Werkzeug zur Erhebung von implizitem Wissen als mögliche Lösung für diese technischen und organisatorischen Herausforderungen prüfen.
Erhebung impliziten Wissens
Im Zentrum des vorliegenden Artikels steht die Erhebung (engl.: elicitation) impliziten Wissens. In [12] werden unterschiedliche Methoden zur Wissenserhebung mithilfe einer Literaturanalyse gesammelt und gegenübergestellt. Bei der Methodenauswahl wird berücksichtigt, dass meistens eine Kombination verschiedener Methoden zur Wissenserhebung nötig ist, um Wissen ganzheitlich zu erfassen. Durch eine Kombination unterschiedlicher Methoden können die Schwächen einzelner Methoden kompensiert werden [12, 13].
Als besonders geeignet zur Erhebung impliziten Wissens und insbesondere „tacit knowledge“ werden unstrukturierte und semi-strukturierte Interviews in Kombination mit Beobachtung identifiziert [12]. Interviews sind die meistgenutzte Methode zur Wissenserhebung [13]. Durch Beobachtung kann auch Wissen erfasst werden, welches nicht oder nur schwer sprachlich ausgedrückt werden kann [12, 13]. Für diese Studie werden Interviews als Methode zur Wissenserhebung gewählt.
Laut Shadbolt et al. [13] können Interviews zwischen strukturierten, semi-strukturierten und unstrukturierten Interviews unterschieden werden. Unstrukturierte Interviews haben keinen festen Ablauf und keine thematischen Grenzen. Durch diese Form des Interviews kann ein Überblick über das Thema geschaffen werden und der/die Interviewte kann die Schwerpunkte des Gesprächs mitbestimmen. Im Gegensatz dazu folgen strukturierte Interviews einer festen Struktur und verwenden vorgegebene Fragestellungen, z. B. „Could you tell me about a typical case?“ oder „Why would you do that?“. Diese Struktur erleichtert später eine Auswertung des Interviews, sorgt dafür, dass nur thematisch Wichtiges besprochen wird, und steigert somit die Effizienz. Ein Nachteil, der sich durch die feste Struktur ergibt, ist das mögliche Übersehen von Themen – vor allem bei einem ersten groben Überblick. [13]
LLMs als Werkzeug zur Wissenserhebung
Gegenwärtige technologische Fortschritte im Bereich der generativen künstlichen Intelligenz, insbesondere LLMs, versprechen eine tiefgreifende Transformation des betrieblichen Wissensmanagements [14]. LLMs wie GPT von OpenAI, Inc. basieren auf riesigen Trainingsdatensätzen und können menschenähnliche Sprache verstehen und generieren [15, 16]. Damit eröffnen sie neue Möglichkeiten zur Erfassung, Strukturierung und Kontextualisierung von Wissen [17, 18]. Derartige Systeme ermöglichen eine niedrigschwellige Erhebung von Erfahrungswissen – z. B. über Voice-to-Text-Anwendungen.
Trotz des technologischen Fortschritts bestehen Herausforderungen bei der Implementierung von LLMs zur Konservierung impliziten Wissens im industriellen Kontext. Dazu zählen u. a.:
- fehlende Validierungsmechanismen, da LLMs nicht über inhärente Logikprüfung verfügen [17]
- Datenschutz- und Sicherheitsfragen bei der Integration unternehmensspezifischer Inhalte [19]
- Akzeptanzprobleme auf Mitarbeiterebene aufgrund von Skepsis oder technischer Überforderung [20]
- unklare Verantwortlichkeiten bei der Pflege und Nutzung der Wissensbasis [16]
Für den erfolgreichen Einsatz von LLMS zur Erhebung impliziten Wissens erscheint es unabdingbar, entsprechende Systeme derart zu gestalten, dass diese nicht nur technologisch einwandfrei funktionieren, sondern auch niederschwellig angewandt und nutzerzentriert konzeptioniert werden [3].
Im Zuge dieser Studie wird nun vorab die Zuverlässigkeit und Qualität der Wissenserhebung exemplarisch mit einem LLM begutachtet. Es wird folglich die Forschungsfrage beantwortet, inwieweit LLMs als Werkzeug bei den oben erwähnten technischen und organisatorischen Herausforderungen unterstützen können. Die Studie umfasst dabei explizit noch nicht die Verifikation mit anderen Wissensquellen und keine Diskussion der nötigen technischen und sozialen Rahmenbedingungen wie beispielsweise der Datensicherheit.
Artverwandte Studie
Van den Bent et al. [21] untersucht ebenfalls, ob LLMs zur Wissenserhebung geeignet sind. In der Studie besteht der Prozess der Wissenserhebung aus einem unstrukturierten Interview und der anschließenden Ontologieerstellung. Eine Ontologie ist eine Methode zur Konzeptualisierung von Wissen. Sie besteht aus Klassen, Relationen, Regeln und Instanzen [22]. Die Dauer des Interviews und das Verhalten des LLMs während des Interviews sowie die Ergebnisse der Ontologieerstellung werden mit den Resultaten menschlicher Experten verglichen.
Die Studie resümiert, dass bei der Nutzung des LLM GPT-4 von OpenAI Effizienzvorteile während des Interviews realisiert werden können und dieses im Vergleich zu durch reale Personen durchgeführte Interviews strukturierter ist. Jedoch erkennt die Studie schlechtere Ergebnisse im Hinblick auf die Ontologieerstellung. Beispielsweise wurde festgestellt, dass das LLM bei der Ontologieerstellung Informationen ergänzt, die nicht in den Interviews erwähnt werden. Diese Informationen sind teils faktisch korrekt und stammen folglich vermutlich aus den Trainingsdaten des LLMs. [21] Im Rahmen der vorliegenden Studie wird eine andere Methodik als in der Studie von van den Bent et al. [21] verwendet.
Wissenserhebung durch Interviews und Zusammenfassung
In dieser initialen Studie wurde ein personalisierter Chatbot unter Nutzung des LLMs ChatGPT-5 von OpenAI, Inc. (erschienen im August 2025) entwickelt, der Interviews zu beliebigen Themenstellungen mit realen Personen durchführen kann. Es wird ein aktuelleres LLM des gleichen Anbieters oben beschriebenen artverwandten Studie verwendet.
Ziel der Interviews ist die Erhebung impliziten Wissens des Interviewten. Die Interviewten sollen dabei das Interview thematisch lenken können, jedoch nicht vom Thema abweichen und gezielte Fragestellungen zur Vertiefung beantworten. Aus diesem Grund werden im Rahmen der Studie semi-strukturierte Interviews gewählt. Im Gegensatz zur eben erwähnten Studie, bei der eine Ontologie erstellt wird, werden die Ergebnisse des Interviews in dieser Studie durch das LLM im Anschluss an das Interview in strukturierter Form als Textdatei ausgegeben. Diese Zusammenfassung könnte direkt als Dokument in eine Wissensdatenbank integriert werden.
Bei der Erstellung des Chatbots werden die Regeln des Prompt Engineering und die Vorgehensweise von semi-strukturierten Interviews berücksichtigt. Dafür werden die Rolle, das Ziel, Hintergrundinformationen, die Vorgehensweise und das Antwortformat vorgegeben. Auch tiefergreifende Fragen werden als Beispiele im Systemprompt integriert. Zur Optimierung des Systemprompts und somit des Interviewverhaltens werden 15 Interviews geführt, wobei der Systemprompt mithilfe eines anderen Chatbot (basierend auf ChatGPT-5) nach jedem Interview angepasst wird. Dazu werden die Interviews bezüglich Gesprächsführung und Zusammenfassung betrachtet und bei mangelhaftem Verhalten wird die korrekte Vorgehensweise im Systemprompt genauer spezifiziert.
Zur Evaluation werden drei Experten zu neun verschiedenen Themengebieten aus dem Bereich produktionsnaher Innovationen und Prozesse in Interviews befragt. Die Themenauswahl obliegt hierbei den Experten. Die Experten sind Ingenieure, die bereits Erfahrung im Umgang mit LLMs und in der Produktion haben. Das Interview startet mit der Themennennung des Experten und wird dann durch vom Chatbot an das Thema angepasste Rückfragen vertieft. Gegensätzlich hierzu beinhaltet artverwandte Studie nur einen Experten und ein Themengebiet. Analog zu [21] soll die Bewertung zwischen Interview und Endergebnis, d. h. die Zusammenfassung, unterschieden werden. Die Bewertungskriterien inklusive Erklärung sind in Bild 1 dargestellt.
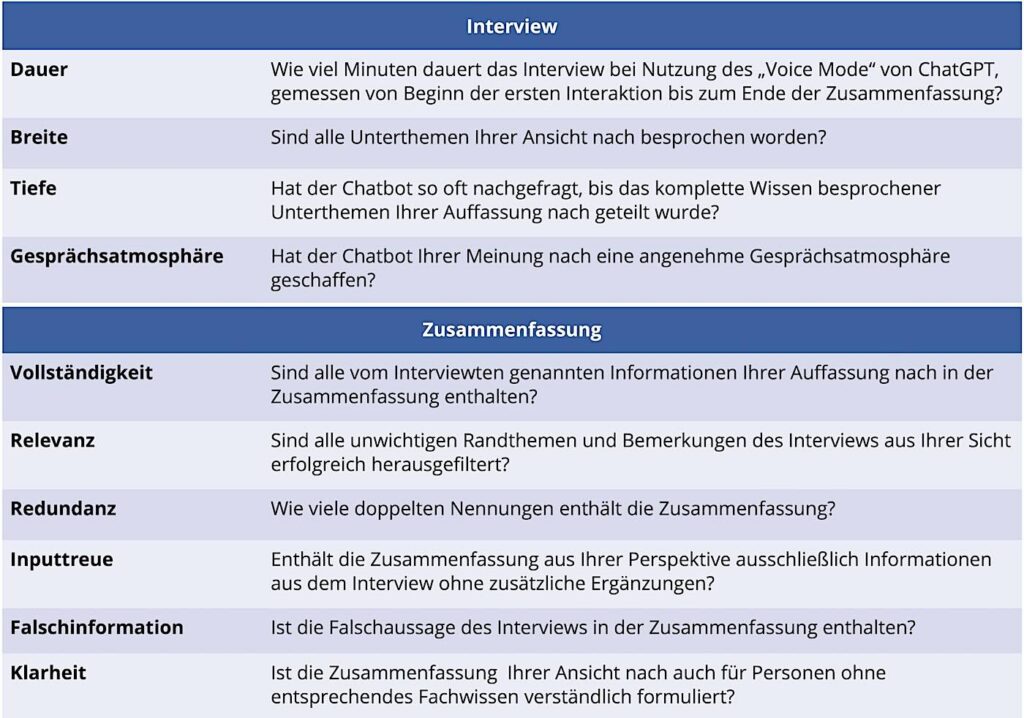
Damit die Dauer des Interviews vergleichbar ist, verwenden alle Experten den „Voice Mode“ von ChatGPT.
In der Studie [21] ist aufgefallen, dass alle von dem LLM erstellten Ontologien halluzinierte Informationen enthalten. Das Kriterium Inputtreue soll diese Erkenntnis überprüfen. Informationen in der Zusammenfassung, die nicht aus dem Interview stammen, werden als negative Bewertung für Inputtreue berücksichtigt. Erweiternd wird das Kriterium Falschinformation eingeführt. Hierzu wurde in jedem Interview durch den Interviewten gezielt eine Falschaussage getätigt.
Das Ziel des Chatbots ist die Erhebung des impliziten Wissens ohne Verifikation mit anderen Wissensquellen, sodass auch Falschaussagen übernommen werden sollen. Grund hierfür ist ein mögliches Aufdecken von neuen Ideen und Konzepten einzelner Mitarbeiter, welche in den vorhandenen Wissensquellen mit einer anderen Vorgehensweise beschrieben sind.
Jeder Experte bewertet im Nachgang zu seinem eigenen Interview dieses und die Zusammenfassung anhand der beschriebenen Kriterien. Anschließend beurteilen die Experten die Zusammenfassung der anderen Kandidaten auf Klarheit. Gesprächsatmosphäre wird im Anschluss an alle eigenen Interviews vom Experten bewertet. Bei den Kriterien Breite, Tiefe, Gesprächsatmosphäre, Vollständigkeit, Relevanz, Inputtreue und Klarheit wird die Bewertung subjektiv vorgenommen, sprich der Experte wählt zwischen „trifft voll zu“, „trifft eher zu“, „trifft eher nicht zu“ und „trifft überhaupt nicht zu. Für Dauer wird die Zeit gemessen, für Redundanz die Anzahl der Doppelnennungen gezählt und für Falschinformation wird überprüft, ob die Falschaussage in die Zusammenfassung übernommen wird.
Interview erzielt bessere Ergebnisse als Zusammenfassung
Die Ergebnisse der Studie sind in Bild 2 und die Durchschnittswerte aller Kriterien mit gleicher Bewertung (eins bis vier) als Balkendiagramm in Bild 3 für einen anschaulichen Vergleich dargestellt.
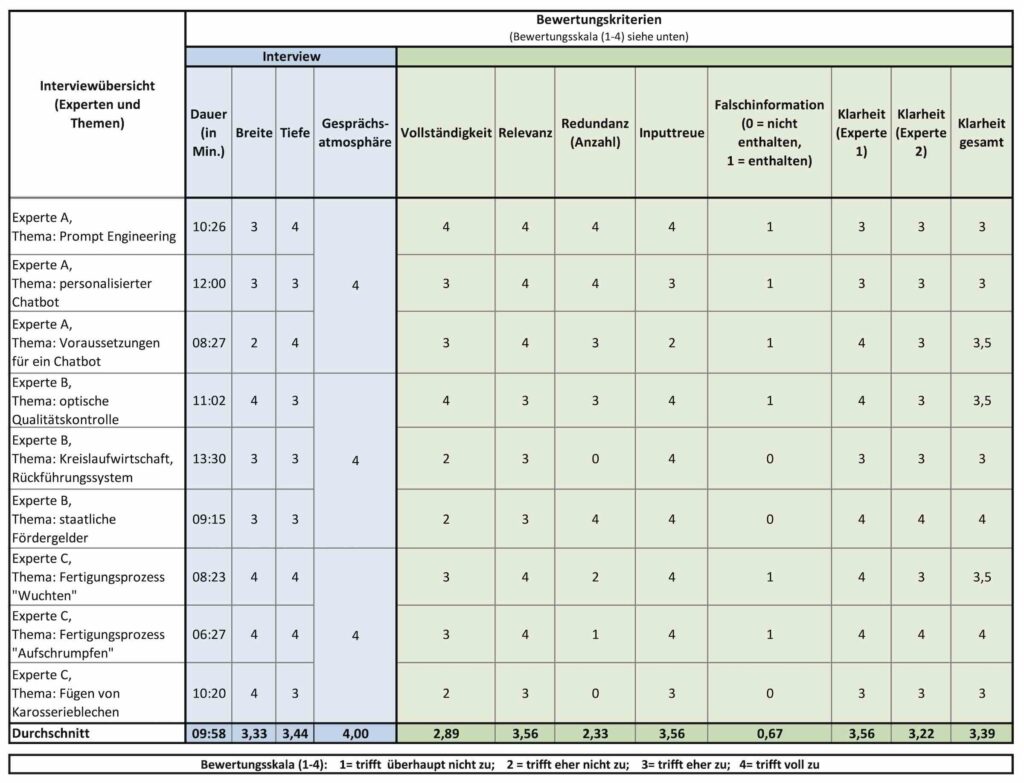
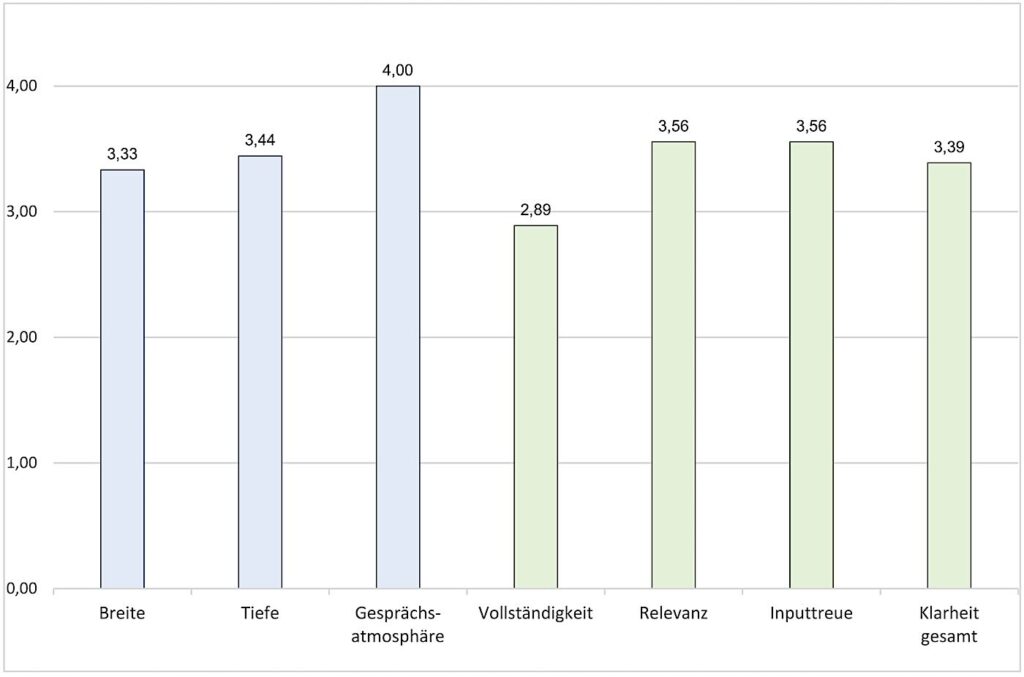
Die Ergebnisse der Studie zeigen ein hohes Potenzial des LLMs im Bereich des Interviews. Dabei fällt auf, dass der Chatbot die Tiefe besser erfragt als die Breite. Die Dauer des Interviews liegt im Schnitt bei etwa zehn Minuten und ist somit ohne großen zeitlichen Aufwand realisierbar. Außerdem ist die Gesprächsatmosphäre mit einer vollen Punktzahl bewertet. Dies ermöglicht den in 1.2 erwähnten Akzeptanzproblemen von Mitarbeitern entgegen zu wirken.
Bei der Zusammenfassung fallen die Werte volatiler aus. Vor allem Vollständigkeit erzielt nur 2,89 Punkte. Folglich sind einige Informationen des Interviews nicht in der Zusammenfassung enthalten. Da das Ziel des Chatbots ist, das implizite Wissen zu erheben, ist eine vollständige Zusammenfassung elementar. Die anderen Kriterien der Zusammenfassung erzielen bessere Ergebnisse. Das LLM scheint unwichtige Informationen weitestgehend herausfiltern zu können (Relevanz) und die Zusammenfassung ist verständlich formuliert – auch für Personen, die nicht über das notwendige Expertenwissen verfügen (Klarheit).
Aufgrund der mangelnden Vollständigkeit muss dieses Ergebnis jedoch etwas differenzierter betrachtet werden. Die Zusammenfassung enthält kaum irrelevante Informationen, jedoch fehlen auch einige wichtige Informationen. Daraus lässt sich folgern, dass der Chatbot vermutlich nicht zuverlässig zwischen relevanten und irrelevanten Informationen entscheiden kann. Im Schnitt weist jede Zusammenfassung 2,33 Doppelnennungen auf (Redundanz). Wünschenswert wäre allerdings eine vollständige Eliminierung der Doppelnennungen.
Im Vergleich zu den Ergebnissen von [21] fallen die Ergebnisse von Inputtreue und Falschinformation positiver aus. Ein möglicher Grund für die Verbesserung kann das Verwenden des aktuelleren Modells und die unterschiedliche Ergebnisdarstellung des LLMs sein. Dies deutet darauf hin, dass eine Zusammenfassung eine geeignetere Darstellung für die Erhebung von implizitem Wissen mit einem LLM ist als eine Ontologie. Bei dem Großteil der Zusammenfassungen verwendet das LLM ausschließlich Informationen aus dem Interview, und sogar faktisch falsche Informationen werden bei sechs von neun Interviews übernommen.
Potenziale und Prämissen
Die vorliegende Studie wurde rund sechs Wochen nach Veröffentlichung des Modells ChatGPT-5 erstellt. Die Gesprächsatmosphäre wurde durch die Interviewten als sehr angenehm empfunden. In der Evaluation hat das Interview besser abgeschnitten als die Zusammenfassung. Grund hierfür ist, dass der Fokus bei der Erstellung des Chatbots auf der Optimierung dessen Interviewverhaltens lag. Dieses Ergebnis kann durch eine höhere Anzahl an vorher geführten Interviews zur Optimierung des Systemprompts verbessert werden.
Aufgefallen sind außerdem die besseren Ergebnisse für Inputtreue und Falschinformation im Vergleich zu Halluzination in der Referenzstudie. Jedoch stellen diese Ergebnisse keine allgemeingültige Aussage dar, wie im vorherigen Kapitel beschrieben wurde. Vor allem die Ergebnisse für Vollständigkeit zeigen Optimierungspotenziale für den praktischen Anwendungsfall.
Trotzdem unterstreichen die Ergebnisse dieser initialen Studie insgesamt das generell hohe Potenzial, LLMs, und speziell ChatGPT-5, im Bereich der Wissenserhebung von implizitem Wissen zu verwenden. Eine Prämisse könnte sein, im Bereich der Zusammenfassung einen menschlichen Experten für eine Konsistenzprüfung einzusetzen. Somit kann auch die anfangs erwähnte Herausforderung, dass LLMs keine inhärente Logikprüfung besitzen, adressiert werden.
Perspektiven für weitere Forschungen
Die Studie liefert Forschungseinrichtungen Anknüpfungspunkte für weitergehende Untersuchungen und lädt Unternehmen ausdrücklich dazu ein, den Einsatz von LLMs zur Erhebung impliziten Wissens zu prüfen. Die Autoren dieser Publikation planen die Durchführung zahlreicher weiterer Interviews mit externen Experten sowie ein Technologie-Benchmarking mit weiteren LLMs. Insbesondere Interviews mit Experten ohne Erfahrung im Umgang mit LLMs sind für ein differenzierteres Ergebnis vorgesehen. Die Ergebnisse dieser Vorstudie bilden die Grundlage für die Entwicklung eines weiterführenden, programmatisch noch anspruchsvolleren Prototyps zur Konservierung impliziten Wissens im Produktionsumfeld.
Dieser Prototyp wird in interessierten Produktionsunternehmen erprobt, validiert und gezielt optimiert. Hierbei soll die Verbesserung der Gesprächsergebnisse, also der Zusammenfassung, einen Schwerpunkt bilden. Ziel ist es, dem Wissensverlust infolge des demografischen Wandels aktiv entgegenzuwirken und zugleich die Wettbewerbsfähigkeit der produzierenden Industrie nachhaltig zu stärken. Die Verifikation mit anderen Wissensquellen im betrieblichen Kontext rundet das weitere Vorgehen ab. Zudem soll im Zuge weiterer Studien eine kritische Betrachtung der Rahmenbedingungen wie Datensicherheit und ethische Fragestellungen beleuchtet werden. Diese initiale Studie beschränkt sich auf die technischen und organisatorischen Herausforderungen zur Erhebung des impliziten Wissens.
Hinweis der Autoren an interessierte Leser: Wie beschrieben streben wir eine Erhöhung der Datenbasis und die damit verbundene Durchführung weiterer Interviews mit externen Experten an. Falls Sie Interesse an der von uns entwickelten Lösung haben oder Sie sich eine Mitwirkung an weiterführenden Studien vorstellen können, laden wir Sie herzlich ein, uns diesbezüglich zu kontaktieren.
Dies ist ein Originalbeitrag. Die englische Übersetzung finden Sie unter der DOI: 10.30844/I4SE.25.6.48
Literatur
[1] Deschermeier, P.; Schäfer, H.: Die Babyboomer gehen in Rente. IW-Kurzbericht, Nr. 78, 2024. URL: https://www.iwkoeln.de/studien/philipp-deschermeier-holger-schaefer-die-babyboomer-gehen-in-rente.html, Abrufdatum 14.07.2025.[2] Statistisches Bundesamt (Destatis): Pressemitteilung Nr. 077 vom 28. Februar 2025: Erwerbstätigkeit im Januar 2025 leicht gesunken, 2025. URL: https://www.destatis.de/DE/Presse/Pressemitteilungen/2025/02/PD25_077_132.html, Abrufdatum 14.07.2025.
[3] Finkel P.; Wurster P.: Unlocking Tacit Knowledge in Industrial Production: Exploring Barriers, Practices, and LLM-Driven Potentials for Knowledge Management [Just Accepted]. In: Proceed. of the 59th Hawaii Int. Conf. on Sys. Sc. (HICSS) (2026).
[4] Ackoff., R. L.: From Data to Wisdom. In: Journal of Applied Systems Analysis (1989) 16, S. 3–9.
[5] Alavi, M.; Leidner, D. E.: Review: knowledge management and knowledge management systems: conceptual foundations and research issues. In: MIS Quarterly 25 (2001) 1, S. 107–36. DOI: https://doi.org/10.2307/3250961.
[6] Fenoglio, E.; Kazim, E.; Latapie, H.; Koshiyama, A.:(2022). Tacit knowledge elicitation process for industry 4.0. In: Discover Artificial Intelligence (2022), 2(1), 6.
[7] Schiedermair, I.; Kick, E.; Baumgartner, M.; Kopp, T.; Kinkel, S.: Wissensmanagement in KMU: Kriterien zur Identifikation von internen Schlüsselpersonen. In: Zeitschrift für wirtschaftlichen Fabrikbetrieb 118 (2023) 6, S. 395–399. DOI: https://doi.org/10.1515/zwf-2023-1087.
[8] Rowley, J.: The wisdom hierarchy: representations of the DIKW hierarchy. In: Journal of information science 33 (2007) 2, S. 163–180. DOI: https://doi.org/10.1177/0165551506070706.
[9] Bostrom, R. P.; Heinen, J. S.: MIS problems and failures: a socio-technical perspective. In: MIS Quarterly 1 (1977) 3, S. 17–32.
[10] Rülicke, S.: Prozessintegriertes Wissensmanagement – eine Lösung im demographischen Wandel. In: Mehlich, P.; Brandenburg, T.; Thielsch, M. (Hrsg): Praxis der Wirtschaftspsychologie – Themen und Fallbeispiele für Studium und Anwendung. Münster 2014, S. 249–263.
[11] Sumbal, M. S.; Tsui, E.; Durst, S.; Shujahat, M.; Irfan, I.; Ali, S. M.: A framework to retain the knowledge of departing knowledge workers in the manufacturing industry. In: VINE Journal of Information and Knowledge Management Systems 50 (2020) 4, S. 631–651.
[12] Hoerner, L.; Schamberger, M.; Bodendorf, F.: Using tacit expert knowledge to support shop-floor operators through a knowledge-based assistance system. In: Computer Supported Cooperative Work (CSCW) 32 (2023) 1, S. 55–91.
[13] Shadbolt, N. R.; Smart, P. R.; Wilson, J.; Sharples, S.: Knowledge elicitation. In: Evaluation of human work (2015), S. 163–200.
[14] Finkel, P.; Wurster, P.: Analysis of the Current State and Best Practices of Knowledge Management Applications in the Manufacturing Industry [Just Accepted]. In: Proceed. of the 19th International Conference Interdisciplinarity in Engineering (2026).
[15] Schönfeld, D.: Anwendungsbeispiele für KI im industriellen Service. In: Altenfelder, K.; Kieffer-Radwan, S.; Schönfeld, D. (Hrsg): Services Management und Künstliche Intelligenz. Wiesbaden 2025. DOI: https://doi.org/10.1007/978-3-658-46665-7_2.
[16] Zur Heiden, P.; Kaltenpoth, S.: Wissensmanagement für Wartung und Instandhaltung im Verteilnetz – Konzeption eines Assistenzsystems basierend auf einem Large Language Model. In: HMD Praxis der Wirtschaftsinformatik 61 (2024), S. 911–926. DOI: https://doi.org/10.1365/s40702-024-01074-3.
[17] Storey, V. C.: Knowledge Management in a World of Generative AI: Impact and Implications [Just Accepted]. In: ACM Transactions on Management Information Systems (2025). DOI: https://doi.org/10.1145/3719209.
[18] O’Leary, D. E.: Large Language Models and the Rebirth of Enterprise Knowledge Management. In: IEEE Computer 57 (2024) 9, S. 20–24.
[19] Hadi, M. U.; Tashi, Q. A.; Qureshi, R.; Shah, A.; Muneer, A.; Irfan, M.; Zafar, A.; Shaikh, M. B.; Akhtar, N.; Wu, J.; Mirjalili, S.: Large Language Models: A Comprehensive Survey of its Applications, Challenges, Limitations, and Future Prospects (2023).
[20] Balzer, V.: Strategische Planung von Produktionskompetenzen. Universität Stuttgart 2024. http://dx.doi.org/10.18419/opus-15010.
[21] Van den Bent, S.; Pernisch, R.; Schlobach, S.: Investigating Knowledge Elicitation Automation with Large Language Models [Under Review]. In: Semantic Web Journal (2025).
[22] Dengel, A.: Wissensrepräsentation. In: Semantische Technologien. Heidelberg 2012, S. 21–72.
Ihre Downloads
Potenziale: Qualifizierung
Lösungen: Prozessmanagement Qualitätsmanagement





