


Auf dem Weg zur grünen Künstlichen Intelligenz (KI) |
KI-Energieeffizienz und die Minimierung des CO2-Fußabdrucks von KI-basierten Systemen
| Zeitschrift | Industry 4.0 Science |
| Ausgabe | 40. Jahrgang, 2024, Ausgabe 6, Seite 18-30 |
| Literatur | Teilen | Zitieren | Download |
Abstract
Keywords
Artikel
KI und Industrie im Zeitalter des steigenden Energiebedarfs: Herausforderungen und Lösungen für eine nachhaltige Entwicklung
Mit der zunehmenden Vernetzung der Welt steigt der weltweite Energiebedarf. Diese Nachfrage wird durch die Notwendigkeit angetrieben, die soziale und wirtschaftliche Entwicklung zu unterstützen. Eine der größten Herausforderungen für den industriellen Energiesektor besteht darin, eine sichere Energieversorgung zu gewährleisten und gleichzeitig seinen Beitrag zum Klimawandel zu verringern [1]. Nachhaltige Entwicklung ist für viele Länder zu einer Priorität geworden, und die Vereinten Nationen haben eine Reihe von 17 globalen nachhaltigen Entwicklungszielen vorgeschlagen, um diese Herausforderung anzugehen [2]. Zu diesen Zielen gehören erschwingliche und saubere Energie, verantwortungsbewusste Produktion und verantwortungsbewusster Konsum sowie Klimaschutzmaßnahmen – alles Maßnahmen, die darauf abzielen, die Kohlenstoffemissionen zu reduzieren und die Klimaproblematik anzugehen.
In den letzten Jahren hat sich das Problem des Klimawandels verschärft. Laut dem Sechsten Sachstandsbericht des IPCC [3] haben sich seit der Veröffentlichung des Fünften Sachstandsberichts im Jahr 2014 [4] weltweit zahlreiche klimabedingte Veränderungen ergeben. Zu diesen Veränderungen gehören der Anstieg der globalen Temperaturen, der Anstieg des Meeresspiegels und die Verschiebung der globalen Niederschlagsmuster.
Die derzeitigen klimapolitischen Strategien und Maßnahmen reichen nicht aus, um die erklärten politischen Ziele zu erreichen. Daher stehen Nachhaltigkeit und die Verringerung des CO2-Fußabdrucks ganz oben auf der Agenda der Unternehmen weltweit. Dies spiegelt sich in der Zahl der Unternehmen wider, die den Climate Pledge unterzeichnet haben: Im Dezember 2022 haben sich 378 Unternehmen mit einer Marktkapitalisierung von insgesamt 15 Billionen US-Dollar dazu verpflichtet, bis 2040 Netto-Null-Emissionen zu erreichen.
Die Liste der Unternehmen, die sich verpflichtet haben, die Ziele des Pariser Abkommens zehn Jahre früher zu erreichen, umfasst Amazon, Best Buy, Henkel, IBM, Mercedes-Benz, Microsoft, Siemens und Unilever. Während solche Initiativen darauf abzielen, den Kohlenstoff-Fußabdruck insgesamt zu verringern, lohnt es sich, die einzelnen Verursacher der globalen Treibhausgasemissionen zu untersuchen.
Bild 1 zeigt, wer zu den weltweiten Treibhausgasemissionen beiträgt, wobei der größte Anteil auf den Energiesektor entfällt. Unter den verschiedenen Industriezweigen tragen Wohngebäude, der Straßenverkehr, die Eisen- und Stahlproduktion und andere Industriezweige erheblich zu den weltweiten Emissionen bei. Die Berechnung der Treibhausgasemissionen für viele Sektoren kann eine Herausforderung sein. Insbesondere im Bereich der Informations- und Kommunikationstechnologie (IKT) müssen verschiedene Aspekte wie die Herstellung von Hardware, Software und Netzwerkverkehr berücksichtigt werden.
Im Jahr 2022 werden weltweit etwa 97 Zettabyte an Daten erstellt, erfasst, kopiert und verbraucht [5]. Die Geräte, die diese Daten erzeugen, verarbeiten und übertragen, benötigen Energie, oft in Form von Strom, was je nach Energiequelle zu erheblichen Kohlenstoffemissionen führt. So sind beispielsweise Rechenzentren für 0,5 % der Kohlenstoffemissionen in den Vereinigten Staaten verantwortlich [6]. KI wird den Strombedarf von Rechenzentren bis 2030 voraussichtlich um 160 % erhöhen, da KI-Technologien wie ChatGPT deutlich mehr Energie benötigen als herkömmliche Dienste.
Dadurch wird der weltweite Energieverbrauch von Rechenzentren von 1-2 % auf 3-4 % ansteigen. Dieser Anstieg wird erhebliche Investitionen in erneuerbare Energien und die Infrastruktur erfordern, wobei die USA 50 Milliarden Dollar für neue Stromerzeugungskapazitäten benötigen und Europa über 1,6 Billionen Dollar, um sein Netz aufzurüsten und den wachsenden Energiebedarf zu decken, während sich die Kohlenstoffemissionen von Rechenzentren voraussichtlich mehr als verdoppeln werden [7].
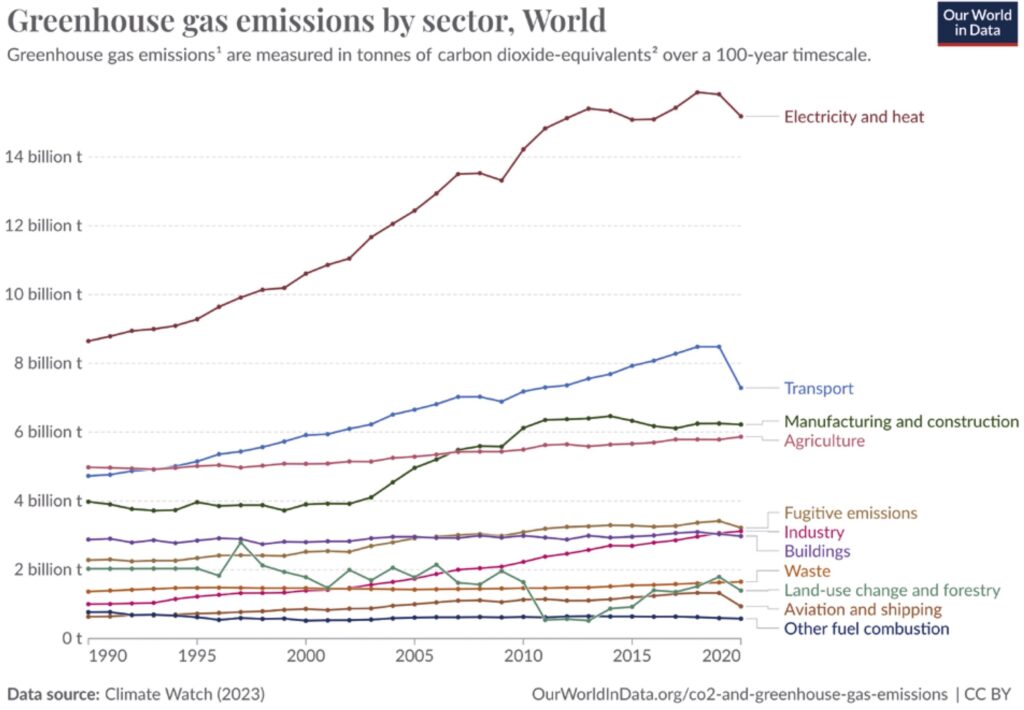
Zahlreiche Studien haben den Beitrag des IKT-Sektors zu den Treibhausgasemissionen untersucht, die in [9] zusammengefasst sind. Sie argumentieren, dass die Emissionen des IKT-Sektors auf der Grundlage überprüfter Schätzungen zwischen 1,8 % und 2,8 % der weltweiten Emissionen liegen, wobei der tatsächliche Anteil möglicherweise zwischen 2,1 % und 3,9 % liegt. Diese Schätzungen variieren aufgrund der unterschiedlichen Annahmen der Analysten und der damit verbundenen Unsicherheiten. [8] kommt zu dem Schluss, dass die IKT-bedingten Treibhausgasemissionen ohne erhebliche Anstrengungen der politischen Entscheidungsträger und der Industrie wahrscheinlich nicht zurückgehen, sondern sogar noch zunehmen werden.
Seit vielen Jahren sind die CO2-Emissionen ein zentrales Thema für Transport- und Logistikunternehmen. Der Transportsektor trägt mit einem Anteil von 11 % an den Gesamtemissionen erheblich zu den Treibhausgasemissionen bei und nimmt weiter zu [10] . Unternehmen wie Maersk, Lineage Logistics, Paack Logistics, FedEx (mit der Verpflichtung zum klimaneutralen Transport bis 2040), DHL und UPS (mit dem Ziel für 2050) haben den Climate Pledge unterzeichnet.
Während verschiedene Mechanismen zur Verringerung der Transportemissionen eingeführt wurden (z. B. grüne Kraftstoffe, Kohlenstoffausgleich, Berichterstattung, Optimierung), wurden die IT-bezogenen Emissionen vernachlässigt. Diese Emissionen werden jedoch für Transport- und Logistikunternehmen immer wichtiger. Große Datenmengen (einschließlich Sendungen, Kunden, Knotenpunkte, Karten und Routen) werden von Logistikunternehmen gespeichert, analysiert und verarbeitet. Es gibt zahlreiche Möglichkeiten, solche Emissionen zu vermeiden oder zu reduzieren, die in dieser Studie weiter untersucht werden.
Moderne IT-Technologien (z. B. mobiles Internet, künstliche Intelligenz, Cloud-Technologien, das Internet der Dinge (IoT) und Robotik) bieten zahlreiche geschäftliche Vorteile für Logistikunternehmen, wie z. B. die Optimierung von Routen oder die Vorhersage von Kundenpräferenzen. Die Übertragung, Speicherung und Verarbeitung von Daten erfordert jedoch viel Energie, was je nach Strommix zu CO2-Emissionen führt.
Der weltweite Internetverkehr, d. h. der Datenfluss über das Internet, wird im Jahr 2022 schätzungsweise 4,2 Zettabyte erreichen [11], was darauf hindeutet, dass eine ineffiziente Digitalisierung das Klima gefährdet. Das Training eines innovativen KI-Modells kann so viel Energie verbrauchen wie 300 Hin- und Rückflüge von San Francisco nach New York oder der gesamte Lebenszyklus von 5 Autos, einschließlich Kraftstoff [12].
Green AI und Clean IT: Ansätze zur Maximierung der Energieeffizienz und Minimierung des CO2-Fußabdrucks
In diesem Beitrag soll Green AI als Methode zur Maximierung der Energieeffizienz von Künstlicher Intelligenz (KI) und damit zur Verringerung des CO2-Fußabdrucks von KI-basierten Systemen untersucht werden. Der Begriff „Grüne KI“ bezieht sich auf KI-Forschung, die innovative Ergebnisse unter Berücksichtigung der Rechenkosten hervorbringt und eine Reduzierung der verwendeten Ressourcen fördert [13].
Green AI ist Teil des Clean-IT-Konzepts, das die „Analyse und Praxis der Entwicklung, Herstellung und Nutzung von Computerhardware, -software und -kommunikationssystemen umfasst, die effizient und effektiv sind und nur minimale oder gar keine Auswirkungen auf die Umwelt haben“ [14]. „Clean IT“ bezieht sich auf den Entwurf, die Entwicklung und den Einsatz von energieeffizienter Hardware, Software und Systemen, die die Auswirkungen auf die Umwelt minimieren, insbesondere durch die Verringerung des Energieverbrauchs und der CO2-Emissionen während des gesamten Lebenszyklus von KI und IT-Betrieb.
Obwohl das Thema auch Fragen wie Entsorgung und Recycling, Compliance, Green Labeling für IT-Produkte und die Minderung von Umweltrisiken umfasst, stehen diese Aspekte nicht im Mittelpunkt dieser Studie. Stattdessen wird Clean IT aus vier verschiedenen Perspektiven untersucht:
- KI-Modell-Perspektive: Wie können komplexe KI-Modelle auf energieeffiziente Weise trainiert werden? Dabei geht es oft um einen Kompromiss zwischen Modellgenauigkeit und Ressourcenverbrauch (Energieeffizienz).
- KI-Algorithmus- und Datenbankperspektive: Wie können Datenbanken und Algorithmen so gestaltet werden, dass der Energieverbrauch während des Betriebs minimiert wird? Das Konzept der „nachhaltigen Programmierung“ behandelt in diesem Zusammenhang verschiedene Aspekte der Softwareentwicklung.
- AI Data Center Perspective: Wie können Rechenzentren hinsichtlich ihres Energieverbrauchs optimiert werden? Dabei werden sowohl Cloud- als auch On-Premises-Lösungen berücksichtigt.
- AI Organization Perspective: Wie kann eine Organisation mit energieeffizienten IT-Geräten ausgestattet werden? In diesem Abschnitt wird das Konzept der Total Cost of Ownership vorgestellt.
Diese Perspektiven müssen als Designobjekte betrachtet und so konstruiert werden, dass die KI-Nutzung (Anwendungsfälle wie KI-Training, Testen, Inferencing, Verfeinerung) am besten den Zielen der Energieeffizienz und des CO2-Fußabdrucks entspricht.
KI und Nachhaltigkeit: Balance zwischen Leistung und Umweltauswirkungen
KI-Modelle und maschinelles Lernen haben aufgrund der Verfügbarkeit großer Datensätze, Hardwareverbesserungen und Leistungssteigerungen, wie sie durch Cloud Computing möglich sind, erhebliche Erfolge erzielt. In [15] wird eine Vielzahl von Bereichen und Tools aufgeführt.
Allerdings verbrauchen große KI-Modelle wie neuronale Netze und Large Language Models (LLMs) erhebliche Mengen an Energie, was aufgrund von Rechenzeit und -aufwand zu Treibhausgasemissionen führt. Während herkömmliche Algorithmen des maschinellen Lernens (ML) eine Leistungsschwelle erreichen, ab der sich die Vorhersagen nicht mehr verbessern, steigern Deep-Learning-Modelle ihre Leistung mit zunehmender Datenmenge weiter [16]. Obwohl die Fähigkeiten technischer Systeme noch nicht mit der menschlichen Intelligenz mithalten können, können Maschinen den Menschen bei bestimmten Aufgaben, wie der Bilderkennung, bereits übertreffen [17, 18].
Dies zeigt, dass Deep Learning darauf abzielt, die Genauigkeit von KI-Modellen ohne rechnerische Einschränkungen zu verbessern. Häufig werden Grafikprozessoren (GPUs) verwendet, um das Training zu beschleunigen im Vergleich zu Zentraleinheiten (CPUs), was zu einem hohen Energieverbrauch beim Training führt. Bei der Verarbeitung natürlicher Sprache führen die Modellkomplexität und die Trainingszeit zu hohen Kosten [11].
Der unterschiedliche Energieverbrauch und die unterschiedlichen Emissionen der verschiedenen KI-Anwendungen stellen eine Herausforderung dar, da nur wenige ML- und KI-Experten wissen, wie man den CO2-Fußabdruck verringern kann. Nicht alle Algorithmen müssen häufig neu trainiert werden, aber in einigen Bereichen wird regelmäßig und täglich neu trainiert, was den Energieverbrauch drastisch erhöht [19]. Daher besteht ein Bedarf an einer verbesserten Effizienz der Algorithmen und einer Quantifizierung der Daten und Berechnungen beim KI-Training [20], um sicherzustellen, dass KI als umweltbewusst und nachhaltig angesehen werden kann, indem unnötiger Energieverbrauch und CO2-Emissionen reduziert werden.
Während sich „Green Computing“ in erster Linie auf Hardware- und Cloud-Mechanismen konzentriert hat, wurde die algorithmische Effizienz von KI noch nicht berücksichtigt. Zwar gibt es bereits Ansätze zur Schätzung der algorithmischen Treibhausgasemissionen, doch sind deren breite Anwendbarkeit, die Notwendigkeit der Selbstüberwachung des Stromverbrauchs und die Einschränkungen bei der Auswahl von Hardware und Software für KI-Aufgaben nach wie vor begrenzt [19]. Daher besteht ein Bedarf an einer breit anwendbaren Methode zur Bewertung der Emissionen und des Energieverbrauchs von KI-Anwendungen und ihrer Reduzierung durch Managementmaßnahmen.
Methodischer Ansatz für Green AI – das „Green AI-Realisierungskonzept“
In einer Design-wissenschaftlich orientierten Art und Weise [21] soll eine Methode zur Messung, Visualisierung und Überwachung des Energieverbrauchs von KI-basierten Systemen geschaffen und getestet werden, um daraus Empfehlungen für die Gestaltung eines grünen und nachhaltigen Einsatzes von KI in Organisationen abzuleiten. Dies wird im Folgenden als Green AI bezeichnet und betrachtet eine KI als grün und nachhaltig, in dem Sinne, dass sie (I) die geringstmögliche Menge an Energie verbraucht, (II) die geringstmögliche Menge an Kohlenstoffemissionen verursacht, (III) die Aufgabe der KI rechtzeitig und (IV) in der geforderten Qualität erfüllt. Es werden verschiedene Perspektiven berücksichtigt, die verschiedene Artefakte erfordern, wie sie in Bild 2 dargestellt sind.
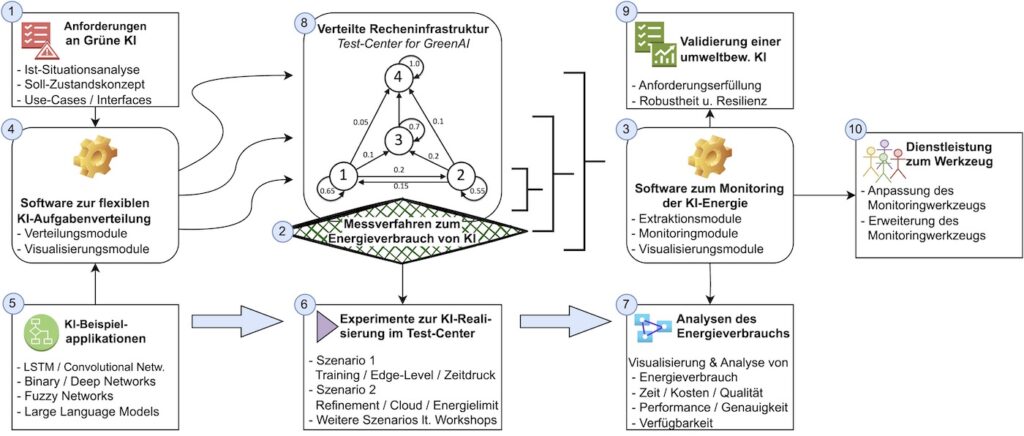
Zu Beginn werden die Anforderungen an die Grüne KI gesammelt (siehe Artefakt 1 in Bild 2). Am Ende des Forschungszyklus werden diese zur Validierung der Grünen KI und der erstellten Artefakte verwendet (siehe Artefakt 9 in Bild 2). Da es jedoch keine allgemein anerkannte Methode gibt, um die Emissionen und den Energieverbrauch von KI-Anwendungen zu bewerten und sie durch Management zu reduzieren, wird eine Messmethode entwickelt, um den Energieverbrauch von KI genau zu messen (siehe Artefakt 2 in Bild 2). Das entwickelte Verfahren und die Werkzeuge werden in dem zu diesem Zweck an der Universität Potsdam einzurichtenden „Testzentrum für Green AI“ getestet (siehe Artefakt 8 in Bild 2).
Dieses wird den in [22] dargestellten Designprinzipien folgen und realistische CPU- und GPU-Geräte für die KI-Realisierung bereitstellen. Die Tests werden sich auf Experimente (siehe Artefakt 6 in Bild 2) mit verschiedenen KI-Beispielanwendungen (siehe Artefakt 5 in Bild 2) stützen. Vertiefende Analysen sollen Energieverschwendung sowie irrelevante CO2-Emissionen aufklären. Artefakt 3 in Bild 2 soll die KI-Energie überwachen, so dass sowohl Softwareroutinen als auch ein manuelles Management eingreifen können.
Artefakt 4 in Bild 2 soll KI-Aufgaben charakterisieren und für effiziente und energieoptimale Verteilung in heterogenen IT-Infrastrukturen sorgen. Anhand verschiedener KI-Beispielanwendungen können unterschiedliche Verteilungsstrategien in hinsichtlich Energieeffizienz und CO2-Emissionen analysiert werden. Schließlich können professionelle (Werkzeug-)Dienstleistungen (siehe Artefakt 10 in Bild 2) die energie- und CO2-optimierte Nutzung von KI während des Lebenszyklus der KI verbessern.
Anforderungen an die Überwachung des Energieverbrauchs und des CO2-Fußabdrucks von KI
Internetrecherchen, die Untersuchung von Aufsätzen, acht Kundenworkshops sowie 14 KMU-Interviews haben dazu beigetragen, die Anforderungen an ein Tool namens Carbon Monitor zu ermitteln.
Darüber hinaus sollte ein Überwachungsinstrument, das sich auf den KI-Energieverbrauch und den CO2-Fußabdruck konzentriert, die folgenden Funktionen bieten.
- Nachverfolgung von Echtzeitemissionen: Ein wichtiges Merkmal von Carbon Monitor ist die Fähigkeit, den Stromverbrauch der zugrunde liegenden Hardware-Infrastruktur kontinuierlich zu überwachen. Durch die Messung des Stromverbrauchs in regelmäßigen Abständen liefert das Tool den Entwicklern sofortige Daten über die Kohlenstoffemissionen, die bei Rechenaufgaben entstehen, und ermöglicht so eine fundiertere Entscheidungsfindung.
- Berechnung der Kohlenstoffintensität: Das Tool verbessert die Genauigkeit der Emissionsberichterstattung durch die Berechnung der Kohlenstoffintensität des verbrauchten Stroms auf der Grundlage des lokalen Energiequellenmixes. Diese Anpassung ermöglicht regionsspezifische Emissionsdaten, die die tatsächlichen Umweltkosten des Stromverbrauchs in verschiedenen geografischen Gebieten widerspiegeln.
- Offene Daten zur globalen Kohlenstoffintensität: In Anbetracht des globalen Charakters vieler Rechenaufgaben, insbesondere derer, die in offenen Cloud-Umgebungen ausgeführt werden, enthält der Carbon Monitor Messdaten zur Kohlenstoffintensität von großen Cloud-Anbietern wie Google Cloud Platform, Amazon Web Services und Microsoft Azure [23]. Diese Funktion hilft Entwicklern bei der Bewertung der Kohlenstoffauswirkungen verschiedener Rechenzentrumsstandorte und erleichtert umweltfreundlichere Entscheidungen über das Datenhosting.
- Kontextbezogener Vergleich: Um die Kluft zwischen abstrakten Emissionsdaten und greifbarem Verständnis zu überbrücken, kontextualisiert der Carbon Monitor seine Ergebnisse, indem er sie mit alltäglichen Aktivitäten gleichsetzt. Durch den Vergleich der berechneten Emissionen mit gewöhnlichen Aktivitäten wie Autofahren oder Fernsehen macht das Tool die Daten für ein breiteres Publikum zugänglicher und nachvollziehbarer.
- Detaillierte Informationen zum Output: Das Tool bietet eine umfassende Reihe von Ausgaben, einschließlich der Berechnungszeit , des Stromverbrauchs in Kilowattstunden und der Emissionen in Kilogramm CO2-Äquivalenten. Darüber hinaus werden kontextbezogene Details wie das Land, der Cloud-Anbieter und der Standort des Servers angegeben, um einen ganzheitlichen Überblick über die Umweltauswirkungen zu erhalten.
- Modelloptimierung und -vergleich: Neben der Nachverfolgung unterstützt der Carbon Monitor auch die Optimierung von Modellen des maschinellen Lernens, indem er den Entwicklern ermöglicht, die Kompromisse zwischen Modellgenauigkeit und Energieeffizienz abzuwägen. Diese Fähigkeit unterstützt die Entwicklung nachhaltigerer KI-Anwendungen, indem sie die Priorisierung von Modellen auf der Grundlage ihrer Leistung und Umweltauswirkungen ermöglicht.
Design und Entwicklung eines AI Carbon Monitor
Das Green Algorithms Dashboard von [19] bietet einen grundlegenden Ansatz zur Abschätzung der Kohlenstoffemissionen verschiedener Algorithmen, die in Disziplinen wie Physik, Atmosphärenwissenschaften und maschinelles Lernen verwendet werden. Dieses Dashboard ist für die Festlegung von Benchmarks und den Vergleich des Kohlenstoff-Fußabdrucks von Rechensystemen in verschiedenen wissenschaftlichen Bereichen von großer Bedeutung. Da die Entwickler die Notwendigkeit erkannt haben, die Auswirkungen ihrer Arbeit auf den Kohlenstoffausstoß zu überwachen und zu verstehen, insbesondere während der Entwicklung von KI-Modellen, wurde der KRALLMANN Carbon Monitor entwickelt.
Der KRALLMANN Carbon Monitor ist ein ausgeklügeltes, auf Python basierendes Tool, das darauf zugeschnitten ist, den CO2-Fußabdruck des Trainings von Machine-Learning-Modellen und anderer Berechnungsaufgaben zu verfolgen und zu verwalten. Es dient der Operationalisierung des Green AI Realization Framework und erfüllt die sechs oben genannten Anforderungen. Dieses Tool lässt sich nahtlos in bestehende Arbeitsabläufe integrieren, um die Überwachung und Verwaltung des CO2-Fußabdrucks in Verbindung mit dem Training von Machine-Learning-Modellen und anderen Berechnungsaufgaben in Echtzeit zu ermöglichen.
Die Prinzipien, die dem Design und der Entwicklung des Carbon Monitor zugrunde liegen, zielen darauf ab, Entwicklern robuste Werkzeuge an die Hand zu geben, mit denen sie den ökologischen Fußabdruck ihrer Berechnungsaufgaben minimieren können. Das Überwachungswerkzeug bietet detaillierte, Echtzeit- und kontextbezogene Einblicke in die Kohlenstoffemissionen, was dazu beiträgt, die Bemühungen um eine Verringerung der Kohlenstoffauswirkungen der Technologiebranche zu informieren und die umfassenderen Ziele der Nachhaltigkeit bei technologischen Entwicklungen zu unterstützen, obwohl es die Nachhaltigkeit selbst nicht aktiv fördert.
Dieser umfassende Ansatz ist für die Förderung verantwortungsvoller und umweltbewusster Berechnungspraktiken unerlässlich. Der Carbon Monitor gibt wertvolle Informationen wie Dauer in Sekunden, Stromverbrauch in Kilowattstunden (kWh), Emissionen, ausgedrückt in Kilogramm CO2-Äquivalenten (CO2 eq in kg), Ländername, Cloud-Anbieter, wenn die Berechnungen in der Cloud ausgeführt werden, und Cloud-Serverbereich aus. Bild 3 zeigt Beispielansichten des Carbon Monitor. Bild 3 (a) zeigt einen Vergleich des Kohlenstoff-Fußabdrucks mit anderen Aktivitäten wie dem Ansehen eines Films, Autofahren oder Haushaltsverbrauch.
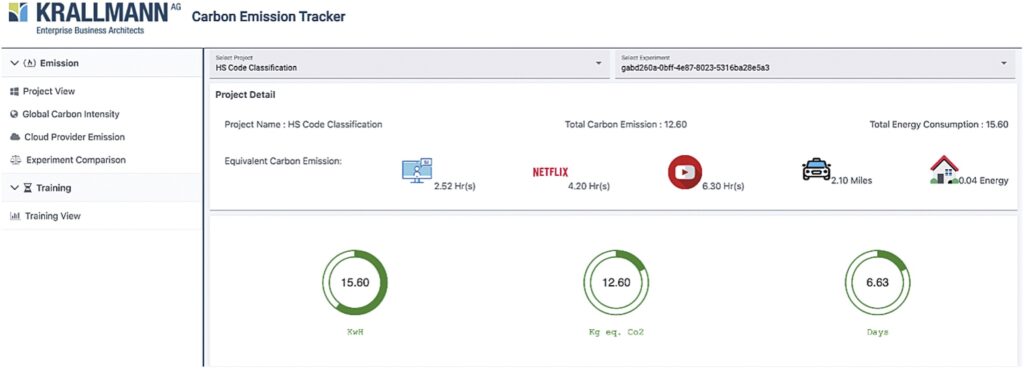
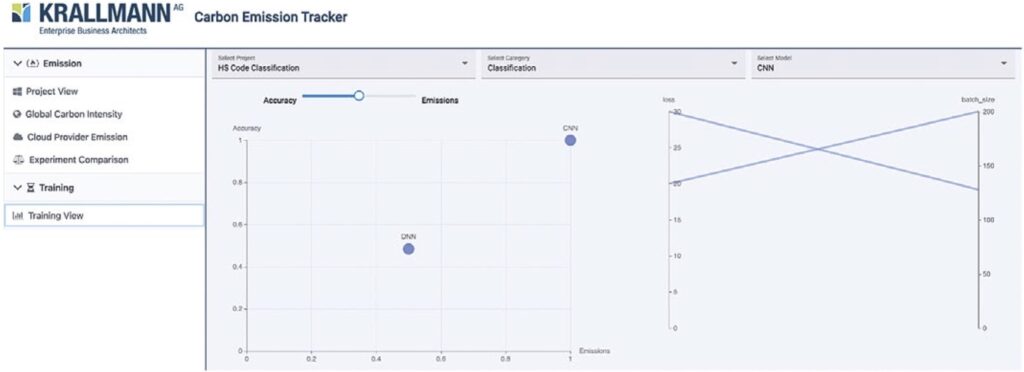
Bild 3(b) zeigt einen Vergleich zwischen den verschiedenen Modellen (hier DNN und CNN). Der Benutzer kann die relative Wichtigkeit der Genauigkeit im Vergleich zu den Kohlenstoffemissionen auswählen und so ein Modell-Ranking erstellen. Im Fall von können der Energieverbrauch der KI und der CO2-Fußabdruck verbessert werden, indem das Modell ausgewählt wird, das den individuellen Zielen und Abwägungen des Managers am besten entspricht.
Um eine tiefergehende Analyse der Umweltfreundlichkeit der KI zu ermöglichen, erlaubt das Tool eine Abwägung zwischen (1) der Genauigkeit der KI-Ergebnisse, (2) der Berechnungszeit, die der entsprechende KI-Anwendungsfall in Anspruch genommen hat, (3) dem Energieverbrauch [in kWh], den die KI-Anwendungsfallrealisierung in Anspruch genommen hat, sowie (4) den Kohlenstoffemissionen (CO2 eq in kg) der KI aufgrund der KI-Anwendungsfallrealisierung. Dies stellt eine erste Version einer Messmethode für den KI-Energieverbrauch dar (vgl. Artefakt 2 in Bild 2).
So ermöglicht es dem Management, einen vielseitigeren Kompromiss zu finden, so dass die grünste KI ausgewählt werden kann , mit dem geringsten Energieverbrauch und den geringsten Kohlenstoffemissionen, während weiterhin KI-Ergebnisse zeitnah und mit einem vertretbaren Maß an Genauigkeit liefert. Ein praktischer Anwendungsfall hierfür wird im nächsten Abschnitt vorgestellt.
Vorführung und Test des Monitors: Beispiel für die Warencode-Klassifizierung
Dieser Abschnitt bietet einen realen Anwendungsfall für die Erstellung einer Green AI im Kontext eines Logistikunternehmens und veranschaulicht den Aufbau einer Green AI durch den Trade-off der vier Dimensionen (1) Genauigkeit, (2) Rechenzeit, (3) Energieverbrauch sowie (4) Kohlenstoffemissionen. Im Rahmen der vorgestellten designwissenschaftlich orientierten Forschung demonstriert den Aufbau einer Green AI und weist die Funktionsweise des entwickelten Carbon Monitors auf einer realistischen Validierungsebene nach.
Die Aufgabe der KI ist die Vorhersage von Warennummern in internationalen Sendungen auf der Grundlage der Artikelbeschreibungen der Absender. Zur Klarstellung: Eine Warennummer ist ein Oberbegriff für verschiedene Waren im Außenhandel. Die Weltzollorganisation hat das „Harmonisierte System (HS)“ festgelegt, das von vielen Ländern verwendet wird. Viele Regionen oder Wirtschaftsräume haben dieses System erweitert. Die Warennummern spielen eine wesentliche Rolle beim grenzüberschreitenden Warentransport. Die richtige Klassifizierung ist entscheidend, um Verzögerungen oder Beschlagnahmungen aufgrund von Zollkontrollen zu vermeiden.
Für den Absender oder Unternehmer ist es wichtig, die richtigen Codes entweder in elektronischer Form oder auf Papier auszufüllen. Es ist sogar eine rechtliche Verpflichtung, den richtigen Code zu verwenden. Aufgrund der Komplexität der Kodierungssysteme kann dies sehr fehleranfällig sein. Erschwerend kommt hinzu, dass ein korrekter Code für eine Lieferung in die EU bei einer Lieferung in die USA falsch sein kann.

Das HS besteht aus allgemeinen Auslegungsregeln (GIR), Abschnitten, Kapiteln, Positionen und Unterpositionen, wie in Bild 4 dargestellt. Bei den Allgemeinen Auslegungsregeln handelt es sich um Regeln , die die Grundsätze für die Klassifizierung von Waren und Gütern unter Verwendung des HS enthalten. Diese sind in 21 Abschnitte unterteilt, und diese wiederum in Kapitel.
Das HS hat 99 Kapitel, die wiederum in Rubriken mit vierstelligen Codes unterteilt sind. Schließlich werden die Rubriken in Unterrubriken unterteilt und mit 6-stelligen Codes versehen.
Da der manuelle Prozess der HS-Code-Korrektur und -Vorhersage aufgrund der geringen Effizienz und Genauigkeit problematisch ist, ist eine automatische HS-Code-Klassifizierung unter Verwendung der Absenderbeschreibung (Deklarationstext) für die Ware unerlässlich. Darüber hinaus wird die Automatisierung der HS-Code-Klassifizierung die Probleme lösen, die sich aus dem Umgang mit einer riesigen Datenmenge, Verzerrungen und unterschiedlichen Bewertungskriterien ergeben.
Deep-Learning-Modelle haben sich zu den beliebtesten Methoden für die Textklassifizierung entwickelt [24]. Heutzutage haben vortrainierte Sprachmodelle wie BERT [25] und ELMo [26] bemerkenswerte Ergebnisse bei der Textklassifizierung und Kategorisierung erzielt. Dennoch ist die Aufgabe der Textklassifizierung im Zusammenhang mit der Klassifizierung von Warennummern eine Herausforderung. Die Klassifizierung des richtigen HS-Codes auf der Grundlage kurzer Textbeschreibungen ist aus folgenden Gründen ein komplexes Problem:
- Textliche Beschreibungen sind kurz, was einen spärlichen Merkmalsraum schafft.
- Die textlichen Beschreibungen folgen eher nicht der Syntax der natürlichen Sprache und sind unstrukturiert.
- Die Anzahl der möglichen Klassen und Labels für die Textklassifizierung ist im Vergleich zu allgemeinen Klassifizierungsaufgaben recht groß.
- Einige Produktkennzeichnungen sind häufiger zu finden als andere.
- Rechtschreibfehler sind verbreitet.
- Wörter, Sätze oder vollständige Beschreibungen, die nur einmal vorkommen, sind häufig.
In Anlehnung an die KI-Konstruktionsmethodik von [27] wurden fünf verschiedene KI-Modelle konstruiert, trainiert und getestet (siehe bis Artefakt 5 in Bild 2). Die wichtigsten Fakten über ihre Konstruktion und den Aufbau des Datensatzes sowie ihre Leistungsbewertung für die Prognose der Warennummern werden im Folgenden in Form eines Benchmarks dargestellt. Zu diesem Zweck wurde ein Datensatz von Importen aus Deutschland verwendet, der von manifestDB erworben wurde. Die Daten werden von Zollbehörden und Spediteuren rund um den Globus gesammelt und von manifestDB weltweit veröffentlicht. Der importierte -Datensatz enthält Datensätze für Sendungen zwischen 2015 und 2021.
Die Schlüsselfelder im Importdatensatz für Deutschland sind die folgenden:
- Name und Anschrift des Versenders
- Ländercode des Schiffes
- WGT (KGS)
- Empfänger
- CMDT-Code
- Zollrechtliche Beschreibung
- Name des Schiffes
Um einen Eindruck von den Daten zu vermitteln, zeigt Bild 5 eine Momentaufnahme des Importdatensatzes für Deutschland von 2015 bis 2021. Die für die Klassifizierung erforderlichen Felder waren CMDT ode (der HS-Code) und die Textbeschreibung mit der Bezeichnung Customs Description.
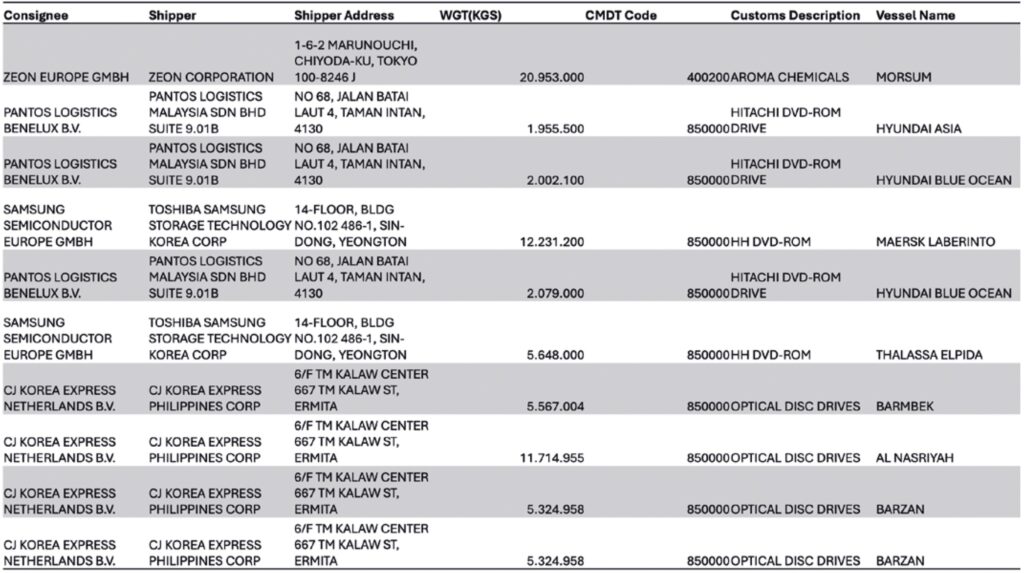
Die Implementierungsphase folgte einem Top-Down-Ansatz, indem der branchenübergreifende Standardprozess für Data Mining CRISP-DM [28] übernommen wurde, der die gemeinsamen Schritte im Lebenszyklus der Datenwissenschaft beschreibt. Es handelt sich dabei um folgende Schritte: Datenvorbereitung (Preprocessing), Aufteilung der Daten, Merkmalsextraktion, Modellauswahl, Modelltraining und Leistungsbewertung des trainierten Modells. In der Phase der Merkmalsextraktion werden TF-IDF, BERT, GPT-2 und Worteinbettungen (Word2Vec, Doc2Vec, FastText) verwendet, um die kanonischen Text-Tokens in Merkmalsvektoren umzuwandeln, die als Eingabe für das Training verschiedener Klassifikationsmodelle geeignet sind.
Die Vorhersagen der Warennummern basierten ausschließlich auf der Artikelbeschreibung des Absenders, die in der Regel nur aus 5-6 Wörtern bestand. Die verschiedenen trainierten Modelle werden anhand ihrer Genauigkeit bewertet. Die Gesamtgenauigkeit unserer HS-6-Vorhersage – nach Entfernung einiger HS-Codes mit geringer Vorhersagegenauigkeit – beträgt 82 % bei Verwendung eines CNN. Die zusätzlichen Erkenntnisse zeigen, dass CNN besser ist als ELMo sowie eine Kombination aus CNN und ELMo.
Darüber hinaus können verschiedene Worteinbettungen (Word2Vec, FastText, Doc2Vec) die resultierende Genauigkeit erheblich verbessern. Es wurden Modelle des maschinellen Lernens wie Random Forests, Support Vector Machines (SVMs) und eine Naïve Bayes-Klassifikation getestet. Insbesondere die SVM führt zu vielversprechenden Ergebnissen, und verbraucht bekanntermaßen weniger Energie.
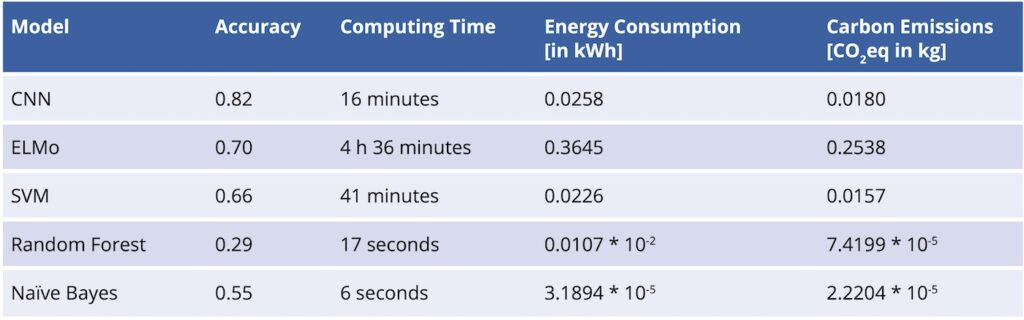
Bild 6 veranschaulicht die Genauigkeit und die Kohlenstoffemissionen in CO2-Äquivalenten in kg für fünf Modelle, die für die Klassifizierung von HS-Codes trainiert wurden. Die fünf verschiedenen Modelle werden für die Vorhersage des korrekten HS-Codes auf der Grundlage der Textbeschreibungen der Absender trainiert, und der Carbon Monitor wird verwendet, um die Kohlenstoffemissionen der einzelnen Modelle während des Trainings zu verfolgen. Da das Experiment für das Training auf einem lokalen Gerät in Deutschland durchgeführt wird, wird die Länderkonstante DEU für die Verfolgung der Emissionen gewählt. Dies stellt den KI-Anwendungsfall eines Trainings auf einem lokalen Gerät in der verteilten Infrastrukturarchitektur des „Test Center for Green AI“ dar (vgl. Artefakt 8 in Bild 2).
Jedes der fünf Modelle wird fünfmal trainiert, und der Kohlendioxid-Energieverbrauch, die Emissionen und die Genauigkeit werden aufgezeichnet. Die Versuchsplanung ermöglichte die Eliminierung lokaler Ausreißer aus den Trainingsläufen. Dies half bei der Identifizierung von signifikanten Ergebnissen (vgl. Artefakt 6 in Bild 2). Ziel war es, ein Modell zu entwickeln, das die Kriterien der minimalen Kohlenstoffbelastung durch das Training und der hohen Genauigkeit erfüllt.
Auf der Grundlage der für eine kleine Teilmenge der Trainingsdaten entwickelten Strategie lässt sich feststellen, dass das CNN-Modell die höchste Genauigkeit und die zweithöchsten Emissionen aufweist. Das ELMo-Modell weist die zweithöchste Genauigkeit und die höchsten Kohlenstoffemissionen auf. Den geringsten Energieverbrauch und die geringsten Emissionen weisen Random Forest und Naïve Bayes auf. Bedauerlicherweise zeigen diese Modelle die schlechteste Leistung bei der Genauigkeit. Bild 7 veranschaulicht den zuvor vorgestellten Benchmark. Er wird vom Carbon Monitor bereitgestellt und vereinfacht so die beste Option für eine energie- und CO2-optimierte KI.
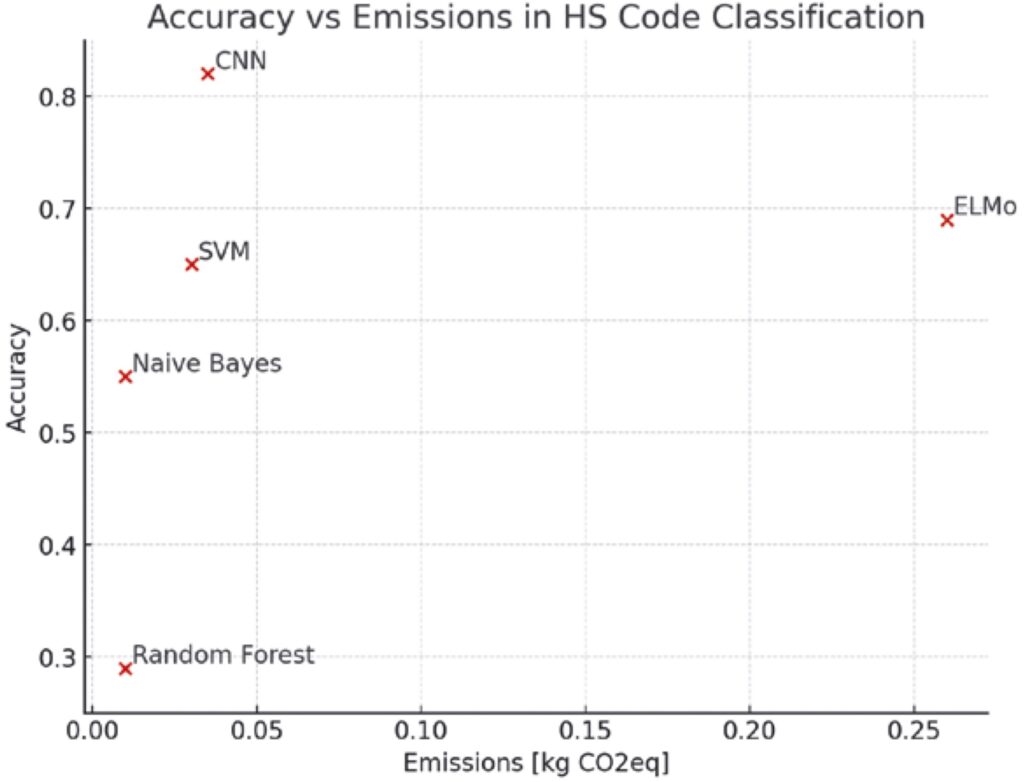
Bild 7 zeigt den Kompromiss zwischen den fünf KI-Modellen, die in den beschriebenen Versuchsläufen realisiert wurden, indem das Genauigkeitsmaß auf der y-Achse und das Emissionsmaß auf der x-Achse dargestellt wird. Auf den ersten Blick scheint CNN die beste Option zu sein. Eine eingehende Analyse auf der Grundlage von Bild 6 und Bild 7 führt jedoch zu folgendem Ergebnis: Die Entscheidung für die Auswahl des endgültigen Modells hängt von der akzeptablen Schwelle ab, die der Benutzer für Genauigkeit und Emissionen festlegt.
Insgesamt zeigt dieser Anwendungsfall, dass es wichtig ist, die Modellentscheidung auf der Grundlage sowohl der Genauigkeit als auch der Kohlenstoffemissionen eines bestimmten Algorithmus zu treffen. In diesem Fall ist CNN eindeutig das genaueste Modell, und seine Kohlenstoffemissionen sind immer noch relativ gering.
Wenn es keine Anforderungen für eine schnelle KI-Ergebnisgenerierung gibt, fällt die Entscheidung für den Anwendungsfall der Warennummernklassifizierung daher zugunsten von CNN aus. Random Forest und Naïve Bayes verbrauchen zwar sehr wenig Energie und emittieren daher wenig Kohlenstoff, ihre Genauigkeit ist jedoch zu gering, um für Unternehmen von Nutzen zu sein. Wenn der Schwerpunkt jedoch auf schnellen Berechnungen liegt, können Random Forest und Naïve Bayes eine Option sein. Angesichts der besseren Genauigkeit von Naïve Bayes im Vergleich zu Random Forest könnte Naïve Bayes eine bessere Wahl als CNN sein, wenn die Ergebnisse in kurzer Zeit vorliegen müssen (z. B. weniger als 60 Sekunden).
Naïve Bayes scheint in diesem Fall die beste Option zu sein. ELMo und SVM sind keine guten Optionen. Sie zeigen eine mittlere Leistung bei der Genauigkeit und eine mittlere Leistung bei der Rechenzeit, dem Energieverbrauch und der Kohlenstoffemission. Leicht bessere Genauigkeitsleistungen können mit ELMo im Vergleich zu SVM gefunden werden, was auf Kosten von Rechenzeit, Energieverbrauch und Kohlenstoffemissionen geht. Wenn es also zum Beispiel einige Unternehmensrichtlinien gibt, die die Verwendung von CNN, Random Forest und Naïve Bayes ausschließen, ist ein echter Kompromiss zwischen ELMo und SVM attraktiv.
Diskussion und Ausblick
Der Artikel hat eine Struktur von Artefakten erstellt, die zur Realisierung einer Green AI erforderlich sind. Darüber hinaus wurde eine Überwachung von fünf KI-Beispielanwendungen für die Vorhersage von Commodity-Code ausgearbeitet. In einem Benchmark wurde ihre Leistung im Detail analysiert, indem vier Dimensionen als Messmethode für den Energieverbrauch von KI kombiniert wurden, nämlich die Dimensionen (1) Genauigkeit, (2) Rechenzeit, (3) Energieverbrauch und (4) Kohlenstoffemissionen.
Die Demonstration und Bewertung der fünf KI-Anwendungsbeispiele hat zu einer kniffligen Abwägungssituation geführt. Hier hängt die Konstruktion einer Green AI – in diesem Beispielsetting hängt dies von der Wahl des geeigneten KI-Modells ab – stark von der Priorisierung der Dimensionen (1) Genauigkeit, (2) Berechnungszeit, (3) Energieverbrauch und (4) Kohlenstoffemissionen sowie der Verfügbarkeit von Organisationsrichtlinien ab. Jedes der vorgestellten Priorisierungsszenarien kann zur Auswahl eines der dargestellten KI-Modelle führen. Die Experimente wurden jedoch nur mit einem lokalen Gerät innerhalb der verteilten Infrastrukturarchitektur des „Test Center for Green AI“ durchgeführt.
Die Ergebnisse können sich ändern, wenn die Realisierung des entsprechenden KI-Anwendungsfalls auf eine der folgenden Varianten umgestellt wird: (1) CPU- versus GPU-Verarbeitung, (2) leistungsfähigere Rechenleistung, (3) alternative Programmierbibliotheken, (4) andere KI-Beispielanwendungen, (5) unterschiedliche Verlagerung auf alternative Rechengeräte in verteilten Infrastrukturen (z. B. von lokaler Verarbeitung zu Cloud-Verarbeitung), (6) weitere Analysedimensionen als Teil der Messmethode für den KI-Energieverbrauch, (7) alternative Gestaltungen von Energie- und Zeitlimits, (8) die Menge der Trainingsmengeneinträge, (9) die Menge der Datenelemente, (10) das Kodierungs- und Dekodierungslayout, (11) die innere Architektur des KI-Modells etc.
Daher werden sich die Forschungen und Experimente zu diesem Gebäude auf deren systematische Untersuchung konzentrieren. Die besten Optionen werden für die Schaffung und den Ausgleich von Green AI erforscht.
Darüber hinaus sind Live-Analysen und Live-Monitoring besonders attraktiv, da (1) die Genauigkeit, (2) die Rechenzeit, (3) der Energieverbrauch und (4) die Kohlenstoffemissionen der KI ad hoc gesteuert werden können. Zusätzlich zu der bereits erwähnten Möglichkeit, die besten KI-Modelle zu ermitteln, können die Verantwortlichen auf diese Weise einen unnötigen Energieverbrauch und hohe Kohlenstoffemissionen verhindern. Zum Beispiel können sie Trainingsläufe einfach abbrechen. Dies trägt weiter dazu bei, eine grüne, energie- und CO2-optimierte KI zu verwirklichen, da überhaupt keine Energie verbraucht wird.
Diese Forschungsarbeit wurde mit Mitteln des Bundesministeriums für Wirtschaft und Klimaschutz aufgrund eines Beschlusses des Deutschen Bundestages unter dem Förderkennzeichen KK5272103MS3 gefördert.
Literatur
[1] Owusu, P. A.; Asumadu-Sarkodie, S.: A review of renewable energy sources, sustainability issues and climate change mitigation. In: Cogent Engineering 3 (2016) 1, 1167990.[2] United Nations: Transforming our world: the 2030 Agenda for Sustainable Development. 2015. URL: https://www.refworld.org/docid/57b6e3e44.html, Abrufdatum 12.10.2024.
[3] IPCC: Climate Change 2022: Impacts, Adaptation, and Vulnerability. Contribution of Working Group II to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change. Edoc UniBasel. 2022. URL: https://edoc.unibas.ch/91322, Abrufdatum 12.10.2024.
[4] IPCC: Klimaänderung 2014. Synthesebericht. Abrufdatum 12.10.2024. URL: https://www.ipcc.ch/site/assets/uploads/2018/02/IPCC-AR5_SYR_barrierefrei.pdf.
[5] IDC & Statista: Volume of data/information created, captured, copied, and consumed worldwide from 2010 to 2020, with forecasts from 2021 to 2025 (in zettabytes) [Graph]. 2021. URL: https://www.statista.com/statistics/871513/worldwide-data-created, Abrufdatum 12.10.2024.
[6] Siddik, M. A. B.; Shehabi, A.; Marston, L.: The environmental footprint of data centers in the United States. In: Environmental Research Letters 16 (2021) 6, 064017.
[7] Sachs, G.: AI is poised to drive 160% increase in data center power demand. In: Goldman Sachs Insights 14 (2024).
[8] Climate Watch (2023) – with major processing by Our World in Data. “Agriculture” [dataset]. Climate Watch, “Greenhouse gas emissions by sector” [original data]. URL: https://ourworldindata.org/grapher/ghg-emissions-by-sector.
[9] Freitag, C.; Berners-Lee, M.; Widdicks, K.; Knowles, B.; Blair, G.; Friday, A.: The climate impact of ICT: A review of estimates, trends and regulations. arXiv preprint arXiv:2102.02622. 2021.
[10] DHL: Green product portfolio. 2022. URL: https://www.dpdhl.com/en/sustainability/environment/green-product-portfolio.html, Abrufdatum 12.10.2024.
[11] International Energy Agency: Digitalisation and energy. 2017. URL: https://www.iea.org/reports/digitalisation-and-energy, Abrufdatum 12.10.2024.
[12] Strubell, E.; Ganesh, A.; McCallum, A. (2019). Energy and policy considerations for deep learning in NLP. arXiv preprint arXiv:1906.02243.
[13] Schwartz, R.; Dodge, J.; Smith, N.A. and Etzioni, O.: Green ai. In: Communications of the ACM 63 (2020) 12, S. 54-63.
[14] Murugesan, S.: Harnessing green IT: Principles and practices. In: IT professional 10 (2008) 1, S. 24-33.
[15] Grum, M.; Sultanow, E.; Friedmann, D.; Ullrich, A.; Gronau, N.: Tools des Maschinellen Lernens. Berlin 2020. URL: https://doi. org/10.30844/grum_2020, Abrufdatum 12.10.2024.
[16] Masson-Delmotte, V.; Zhai, P.; Pirani, A.; Connors, S. L.; Péan, C.; Berger, S.; Zhou, B.: Climate change 2021: the physical science basis. Contribution of working group I to the sixth assessment report of the intergovernmental panel on climate change 2 (2021).
[17] Grosan, C.; Abraham, A.: Intelligent systems Vol. 17, S. 261-268. Springer 2011.
[18] Thomsen, M.: Microsoft’s Deep Learning Project Outperforms Humans in Image
Recognition. In: Forbes Magazine (2015). URL:
https://www.forbes.com/sites/michaelthomsen/2015/02/19/microsofts-deep-learning-
project-outperforms-humans-in-image-recognition, Abrufdatum 12.10.2024.
[19] Lannelongue, L.; Grealey, J.; Inouye, M.: Green algorithms: quantifying the carbon footprint of computation. In: Advanced science 8 (2021) 12, 2100707.
[20] Hernandez, D.; Brown, T. B.: Measuring the algorithmic efficiency of neural
networks. arXiv preprint arXiv:2005.04305. 2020.
[21] Peffers, K.; Tuunanen, T.; Rothenberger, M. A.; Chatterjee, S.: A design science research methodology for information systems research. In: Journal of management information systems 24 (2007) 3, S. 45-77.
[22] Grum, M.; Bender, B.; Alfa, A. S.; Gronau, N.: A decision maxim for efficient task realization within analytical network infrastructures. In: Decision Support Systems 112 (2018), S. 48-59.
[23] Rojahn, M.; Gronau, N.: Openness Indicators for the Evaluation of Digital Platforms between the Launch and Maturity Phase. 2024.
[24] Nam, J.; Kim, J.; Loza Mencía, E.; Gurevych, I.; Fürnkranz, J.: Large-scale multi-label text classification—revisiting neural networks. In: Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2014, Nancy, Frankreich, 15.-19. September 2014. In: Proceedings, Part II 14 (2014), S. 437-452.
[25] Devlin, J.; Chang, M. W.; Lee, K.; Toutanova, K.: Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805. 2018.
[26] Sarzynska-Wawer, J.; Wawer, A.; Pawlak, A.; Szymanowska, J.; Stefaniak, I.; Jarkiewicz, M.; Okruszek, L.: Detecting formal thought disorder by deep contextualized word representations. In: Psychiatry Research 304 (2021), 114135.
[27] Grum, M.: Construction of a concept of neuronal modeling. Springer Nature 2022. URL: https://doi.org/10.1007/978-3-658-35999-7, Abrufdatum 12.10.2024.
[28] Wirth, R.; Hipp, J.: CRISP-DM: Towards a standard process model for data mining. In: Proceedings of the 4th international conference on the practical applications of knowledge discovery and data mining 1 (2000), S. 29-39.
Ihre Downloads
Potenziale: Management Ressourceneffizienz
Lösungen: Prozessmanagement Risikomanagement






