


Fachbereich trifft Code |
Mit KI zur besseren Zusammenarbeit bei der Softwareentwicklung
| Zeitschrift | Industry 4.0 Science |
| Ausgabe | 41. Jahrgang, 2025, Ausgabe 4, Seite 104-110 |
| Literatur | Teilen | Zitieren | Download |
Abstract
Keywords
Artikel
Die zunehmende Vernetzung und Digitalisierung in nahezu allen Wirtschaftsbereichen stellt Unternehmen vor die Herausforderung, immer größere und komplexere Datenmengen effizient zu nutzen [1]. Besonders in datenintensiven Branchen wie der Automobilindustrie oder dem Maschinenbau stehen Unternehmen vor der Aufgabe, heterogene Datenquellen zu integrieren, eine hohe Datenqualität sicherzustellen und die Interoperabilität, also Datenaustauschbarkeit, zwischen verschiedenen Systemen zu gewährleisten [2, 3].
Gleichzeitig steigen die Anforderungen an agile Softwareentwicklungsprozesse, die eine enge Zusammenarbeit zwischen unterschiedlichen Akteuren erfordern – insbesondere zwischen Softwareentwicklungs- und Betriebsteams [4]. Der Erfolg datengetriebener Softwarelösungen hängt dabei maßgeblich von der Kohärenz und Konsistenz der zugrundeliegenden Datenmodelle ab, da eine fehlerhafte oder inkonsistente Datenstruktur die Effizienz von Entwicklungsprozessen und die Qualität der entwickelten Softwareprodukte erheblich beeinträchtigen kann [1, 5].
Eine zentrale Herausforderung besteht darin, dass viele bestehende Modellierungsansätze nicht darauf ausgelegt sind, eine sogenannte semantische Interoperabilität zu gewährleisten [6]. Das bedeutet, dass die (logischen) Zusammenhänge zwischen Daten bei dem Austausch von Informationen nicht berücksichtigt werden. Dies liegt daran, dass klassische Datenmodellierungsverfahren sich primär auf strukturelle Aspekte fokussieren und dabei die explizite Repräsentation der semantischen Bedeutung von Daten, also die Daten in ihrem Kontext beziehungsweise in ihrer Interpretation, vernachlässigen.
Ein Beispiel für eine semantische Bedeutung ist, wenn man etwa den Jaguar in den Kontext Automobil oder Tierreich setzt, und damit entweder die Automarke oder das Tier meint [7]. Ohne diesen Kontext werden Daten zwar formal korrekt modelliert, können jedoch nicht ohne weiteres in unterschiedlichen Systemen verwendet oder interpretiert werden können.
Insbesondere in interdisziplinären Teams, in denen verschiedene Fachbereiche mit unterschiedlichen Begrifflichkeiten und Datenstrukturen arbeiten, führt dies zu Missverständnissen und Ineffizienzen [4]. Dadurch ergeben sich auch erhebliche Herausforderungen in der Kommunikation zwischen Entwicklungs- und Betriebsteams. In vielen Unternehmen sind diese beiden Bereiche nach wie vor organisatorisch getrennt, müssen jedoch bei der Softwareentwicklung zusammenarbeiten [8].
Um diesen Herausforderungen zu begegnen, wird in diesem Artikel eine Methodik zur semantischen Modellierung im Softwareentwicklungsprozess entwickelt, die darauf abzielt, die Datenqualität zu verbessern, Interoperabilität sicherzustellen und die Zusammenarbeit zwischen Entwicklungs- und Betriebsteams zu optimieren. Im weiteren Verlauf werden wir auch noch auf die Unterstützung durch Künstliche Intelligenz eingehen.
Durchgängige Datenmodelle und ihre Bedeutung in der Softwareentwicklung
Datenmodelle repräsentieren die abstrakte Darstellung von existierenden Informationen in Unternehmen und ihren Abteilungen [9]. Informationen können immer dann aus Daten gezogen werden, wenn diesen eine Bedeutung (Semantik) zugewiesen wird [10]. In der Softwareentwicklung sind solche Datenmodelle grundlegend, denn eine Software macht im eigentlichen Sinne nichts anderes, als einen gegebenen Input entsprechend ihrer definierten Funktion in „gewünschten“ Output zu verwandeln, beispielsweise addiert (Funktion) ein Taschenrechner mehrere Zahlen (Input) zu einem Ergebnis (Output) [7]. Für Entwickler ist es notwendig, diesen Input zu kennen, um die Funktion anhand des Outputs überprüfen zu können.
In der Praxis ergibt sich dadurch aber die Herausforderung, dass diese Datenmodelle zwar unter Zuhilfenahme des Wissens des beauftragenden Fachbereichs erstellt werden, jedoch in erster Linie dem Blickwinkel der Entwickler entsprechen. Das liegt mitunter daran, dass sich Fachexperten zwar in ihrem Gebiet, jedoch nicht unbedingt in der Softwareentwicklung und Datenmodellierung auskennen. Das heißt, dass die Wahrscheinlichkeit hoch ist, dass Datenmodelle nicht alle Informationen in ihrem Kontext beinhalten [11].
Ziel ist es deshalb, auch die Fachbereiche in diese Datenmodellierung zu integrieren und eine intuitive Datenmodellierungsgrundlage zu schaffen, die bestehendes Datenmodellierungswissen nutzt. Dadurch wird es ermöglicht, dass Software entsprechend den Bedürfnissen des beauftragenden Fachbereichs entwickelt werden kann, da Entwickler spezifischere Informationen über die Aufgaben, Daten und Prozesse des Fachbereichs bekommen und daher verstehen, warum sie die einzelnen Funktionen benötigen.
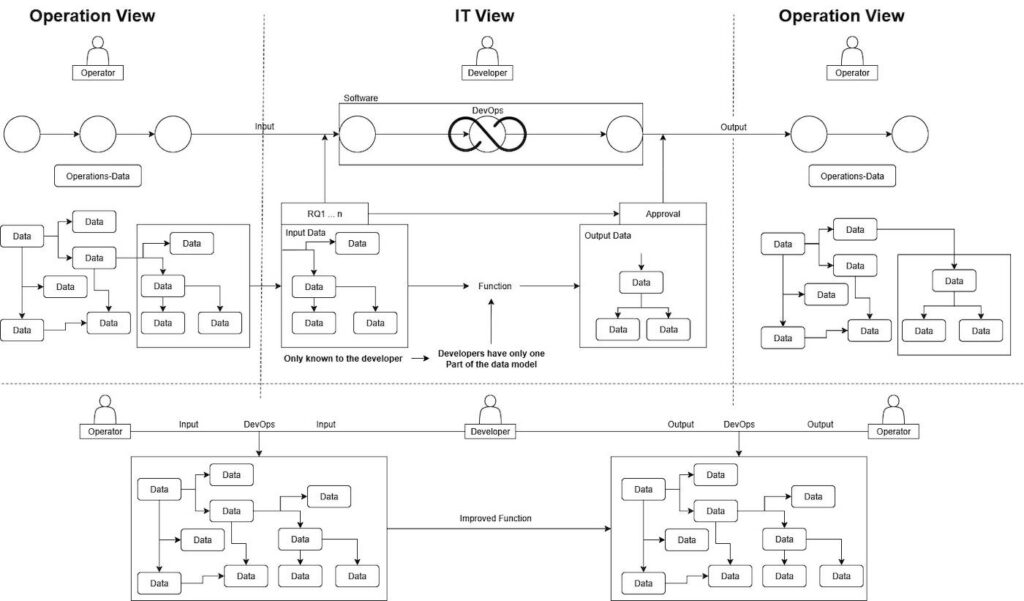
Integration von Fachexperten in den Datenmodellierungsprozess
Wie bereits beschrieben, kann die Integration von Fachexperten die Softwareentwicklung effizienter und schneller machen, jedoch haben nicht alle Fachexperten das notwendige Wissen zur Datenmodellierung. Ein intuitiver Ansatz hilft hierbei, damit auch nicht-IT-affine Personen ihr Wissen in ein Datenmodell einbringen können, das die Daten in ihrem Business-Kontext darstellt.
Somit wird eine Plattform benötigt, die einerseits das Wissen aus dem Fachbereich integriert, ohne dass hierfür Datenmodellierungswissen vorhanden ist, andererseits muss sie einer Syntax entsprechen, der eine Nutzung des Datenmodells für die Entwickler ermöglicht. Fachbereiche müssen ihre Daten einfach eintragen oder aus bestehenden Dokumenten in die Plattform integrieren können und gleichzeitig muss diese Datenintegration die Zusammenhänge der Daten berücksichtigen. Zudem hängt die Genauigkeit des Algorithmus, zu einem gegebenen Input einen passenden Output zu liefern, davon ab, wie umfangreich das Datenmodell ist.
In der Praxis wird ein vollständiges Datenmodell oftmals nicht erreicht, jedoch gibt es eine Korrelation zwischen einem umfangreicheren Datenmodell und einer besseren Realisierung. Modelle wie das Referenzarchitekturmodell RAMI 4.0 [12] zeigen, dass im Business-Kontext Daten eine Hierarchie haben (können), also eine systematische Organisation von Daten in einer Struktur mit über- und untergeordneten Elementen [6]. Dies machen wir uns in unserem Ansatz zunutze, da durch die Einordnung in eine Hierarchie eine Durchgängigkeit von oben nach unten gewährleistet sein muss.
Fehlt diese Durchgängigkeit, da Elemente oder Daten fehlen, dann fällt dies direkt auf. Gleichzeitig hilft es beim Modellieren, da man diese Hierarchie mit einer gewissen Systematik, etwa von oben nach unten, befüllen kann. Neben diesem hierarchischen Datenmodell verwenden wir ein klassisches Ressource-Description-Framework (RDF) [11]. Dies ermöglicht generell logische Aussagen über beliebige Dinge: In unserem Fall lassen sich die Daten semantisch, also ihrer Bedeutung nach, logisch miteinander verknüpfen.
Beispielsweise „Ein Reifen ist Teil eines Autos“ oder „Ein Auto wird in einer Fabrik produziert“ sind solche logischen Aussagen, die in einem RDF-Schema dargestellt werden können [11]. Vorteil davon ist, dass die Fachexperten diese logischen Zusammenhänge in ihrer natürlichen Sprache beschreiben und damit in das RDF-Schema bringen können. Gleichzeitig ermöglicht das RDF-Schema eine Maschinenverständlichkeit, d. h. auch Maschinen und Systeme können diese logischen Zusammenhänge verstehen und weiterverarbeiten.
In seinem Aufbau ähnelt RDF auch einem UML- oder Entity-Relationship-Modell, was weit verbreitete Datenmodelle in der Softwareentwicklung sind [9]. Das heißt, diese Modellierung genügt auch den Anforderungen von Entwicklern zur Erstellung ihrer Software. Wie bereits beschrieben, kann hier die Maschinenverständlichkeit helfen, die Softwareentwickler bei der Programmierung durch Systeme oder auch Künstliche Intelligenz zu unterstützen.
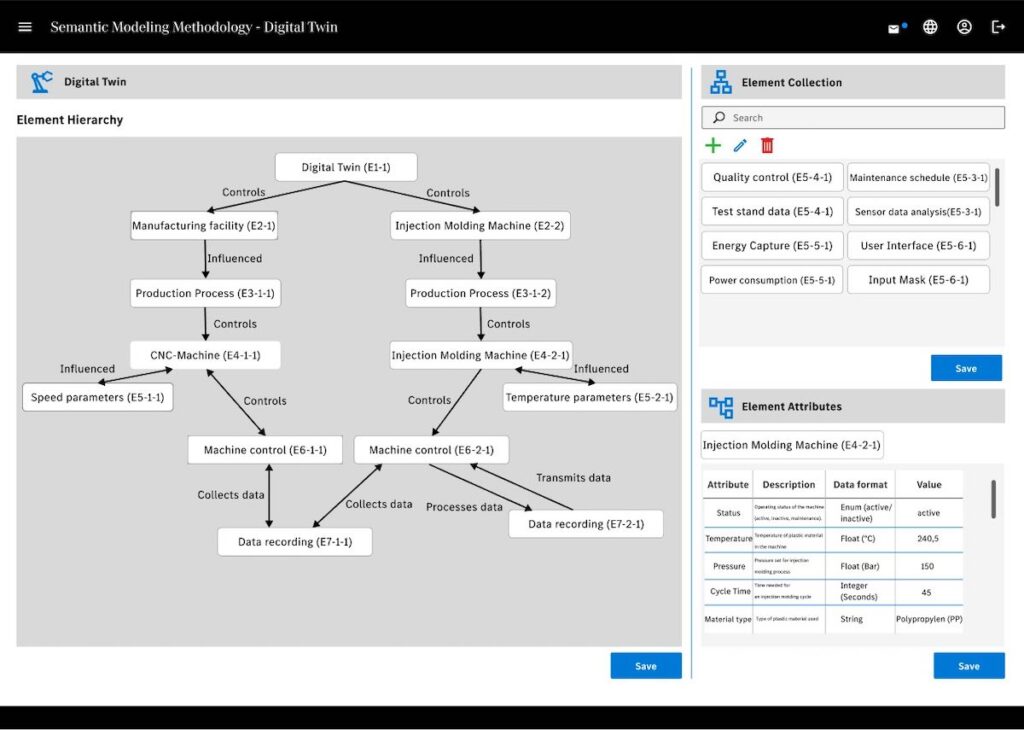
Technische Umsetzung und Integration von Künstlicher Intelligenz
Technisch gesehen ist dieser Ansatz eine Erweiterung innerhalb der klassischen Modellierung, weshalb dieser Ansatz analog zu bestehenden Ansätzen aufgebaut und implementiert werden kann. Die Unterscheidung besteht in der Erweiterung und einer Integration des Fachbereichs, der befähigt werden muss, seinen Input in das Tool zu geben. Eine einfache Lösung wäre hier, dass der Fachbereich die einzelnen Elemente selbst einträgt oder entsprechende Daten hochladen kann. Da der Fachbereich unter Umständen aber mit einer Semantik oder Datenhierarchie nicht vertraut ist, empfiehlt es sich, dass der IT-Bereich bei der Datenintegration unterstützt und gleichzeitig schon einen Überblick über den Bereich erhält.

Die dargestellte Vorgehensweise ist sicherlich zeitintensiver als die klassische Vorgehensweise, auch wenn die Vorteile ersichtlich sind. Jedoch kann in diesem Bereich auch die Künstliche Intelligenz einen Mehrwert bieten, was wiederum mit höheren Kosten verbunden ist, da hier noch keine so weit verbreiteten Standardlösungen existieren. Denkbar ist jedoch, dass Künstliche Intelligenz einerseits dafür sorgt, dass die Daten vollständig sind und auch vollständig miteinander vernetzt sind.
Andererseits kann sie hier auch Teile der Softwareentwicklung übernehmen, wobei das Ergebnis besser ist, je mehr und je genauer die Informationen sind, die die Künstliche Intelligenz erhält.
KI-Modelle wie Copilot auf GitHub oder Gemini helfen bereits heute bei der Erstellung von Software-Code mit einer überraschend hohen Genauigkeit und Robustheit der Algorithmen [13]. Wichtig ist hierbei aber auch zu erwähnen, dass bei diesen Beispielen noch Herausforderungen wie fehlerhafte Codegenerierung, Intransparenz der Modelle und Sicherheitsaspekte zu bewältigen sind.
Trotz dieser Herausforderungen können Entwickler die Künstliche Intelligenz nutzen, um schnell und effizient die Algorithmen und damit die Software entwickeln zu können. Der „Erfolg“ der Software hängt dabei vom gegebenen Input (und dem zu erwartenden Output) ab, sowohl für die menschlichen Entwickler, als auch für die Maschine. Eine hohe Qualität des Inputs, die vorhandenen Zusammenhänge und auch die Vollständigkeit sind hierbei Trumpf zum Verständnis und der damit zusammenhängenden Entwicklung der Software.
Wir sehen hier, dass es deshalb notwendig ist, die Daten grundlegend und ganzheitlich zu erfassen. Wie bereits oben beschrieben, können wir jedoch nicht davon ausgehen, dass die Fachexperten ein vollständiges Modell liefern (können), aufgrund der fehlenden Zeit, spezifischem Wissen oder der Unübersichtlichkeit großer Modelle. Künstliche Intelligenz kann auch hierbei unterstützen und entsprechend ergänzen.
Entweder man „füttert“ diese Künstliche Intelligenz mit dem entsprechenden Wissen durch Dokumente, Websites oder ähnlichem oder man benutzt die grundlegende Idee von Large Language Models, die das nächste Wort mit einer gewissen Wahrscheinlichkeit versehen und somit das höchstwahrscheinlichste Wort ausgeben [13]. Dies kann jedoch bei sehr spezifischen Themen ohne ein umfassendes Training zu Fehlern führen.
Nichtsdestotrotz bietet auch hier KI umfassende Möglichkeiten, das Daten- und damit Domänenverständnis zu erhöhen und Softwareentwicklern bei ihrer Arbeit zu unterstützen. Nutzt man Standardmodelle von KI, so sind einige sogar kostenlos erhältlich, jedoch steigen die Kosten mit zunehmendem Spezifizierungsgrad wegen des Trainings dieser Modelle, weshalb ein Kosten-Nutzen-Abgleich notwendig ist. Gleichzeitig ist auch das Spannungsfeld zwischen Menschen und Maschine zu berücksichtigen. Vorbehalte gegenüber der KI und auch der Grad, in welchem man einer Maschine Verantwortung übergibt, müssen bei der Implementierung berücksichtigt werden. Klar ist, dass sich auch die Künstliche Intelligenz weiterentwickelt und es schwer sein wird, in Zukunft auf sie zu verzichten.
Fazit und Ausblick
In der Softwareentwicklung gibt es oftmals Herausforderungen durch einen fehlenden Austausch zwischen dem Fach- und dem Entwicklungsbereich in dem Maße, dass ein gemeinsames und möglichst ganzheitliches Datenmodell nicht erstellt werden kann. Die Softwareentwicklung nutzt somit nicht das gesamte Potenzial, Software genau nach den Bedürfnissen des Fachbereichs zu entwickeln.
Unter Nutzung einer hierarchischen Darstellung von Daten und der Darstellung in einem RDF-Framework kann mit geringem Aufwand ein Tool erstellt werden, dass das (Daten-)Verständnis von Entwicklern erhöht, den Austausch mit dem Fachbereich fördert und eine gemeinsame Plattform zur Zusammenarbeit ermöglicht.
Klar ist, dass dies mit einem höheren Zeitaufwand verbunden ist. Gleichzeitig ist aber zu erwarten, dass sich das Verständnis der Entwickler erhöht, da sie mehr beziehungsweise genauere Informationen darüber besitzen, welche Herausforderungen die zu entwickelnde Software zu lösen hat.
Unter Zuhilfenahme von etablierten Technologien oder sogar durch KI kann der Nutzen noch gesteigert und Zeit bei der Entwicklung eingespart werden. Klar ist, dass KI immer mehr Bereiche durchdringt und auch die Softwareentwicklung zunehmend unterstützt. Jedoch ist die KI wie auch die Entwickler von einem qualitativ hochwertigen Input abhängig, der in spezifischen Fällen nur vom Fachbereich bereitgestellt werden kann und möglicherweise nicht in schriftlicher oder zweckdienlicher Form vorliegt.
Auch das Spannungsfeld zwischen Mensch und Maschine ist hier zu berücksichtigen, da KI noch in der Entwicklung steckt und Herausforderungen wie Datenschutz, Autonomie der KI und vieles weitere nicht abschließend geklärt ist. Der hier vorliegende Ansatz soll das Verständnis erhöhen und eine Grundlage ermöglichen, mit der es möglich ist, die Softwareentwicklung durch genauere Daten und ihre Semantik zu verbessern. Das ist auch für die zukünftige Entwicklung der Programmierung notwendig, da hier zu erwarten ist, dass der Anteil an KI zunehmen wird.
Literatur
[1] Block, S.: Large-Scale Agile Frameworks. In: Large-Scale Agile Frameworks. Berlin, Heidelberg: 2023, S. 49–66. DOI: 10.1007/978-3-662-62048-9_3.[2] Hinrichs, H.: Datenqualitätsmanagement in Data Warehoue-Systemen, Universität Oldenburg Fakultät II – Informatik, Wirtschafts- und Rechtswissenschaften. 2002.
[3] El Alaoui, I.; Gahi, Y.; Messoussi, R.: Big Data Quality Metrics for Sentiment Analysis Approaches, in Proceedings of the 2019 International Conference on Big Data Engineering, Hong Kong Hong Kong: ACM, Juni 2019, S. 36–43. DOI: 10.1145/3341620.3341629.
[4] Tessem, B.; Iden, J.: Cooperation between developers and operations in software engineering projects. In: Proceedings of the 2008 international workshop on Cooperative and human aspects of software engineering, Leipzig, Germany: ACM, Mai 2008, S. 105–108. DOI: 10.1145/1370114.1370141.
[5] Black, A.; van Nederpelt, P.: Dimensions of Data Quality (DDQ). DAMA NL Foundation, 2020.
[6] Hildebrand, K.; Gebauer, M.; Hinrichs, H.; Mielke, M. (Hrsg): Daten- und Informationsqualität. Wiesbaden 2018. DOI: 10.1007/978-3-658-21994-9.
[7] Lehner, F.; Wildner, S.; Scholz, M.: Wirtschaftsinformatik: Eine Einführung, 2. Auflage. München 2008.
[8] Sharma S.; Coyne, B.: DevOps für Dummies. 2015.
[9] Amberg, M.: Prozeßorientierte betriebliche Informationssysteme. Berlin, Heidelberg 1999. DOI: 10.1007/978-3-642-60191-0.
[10] Wedekind, H.: Lexikon der Wirtschaftsinformatik. Berlin Heidelberg 1997. DOI: 10.1007/978-3-662-08370-3.
[11] Fürber, C.: Data Quality Management with Semantic Technologies. Wiesbaden 2015. DOI: 10.1007/978-3-658-12225-6.
[12] Kaviraju, R. D.: RAMI 4.0 (Reference Architectural Model Industry 4.0): Explained with example, KR Architecture World. URL: https://industry40.co.in/rami-reference-architecture-model-industry-4-0/, Abrufdatum: 27.05.2025.
[13] Joachimiak, M. P. u. a.: The Artificial Intelligence Ontology: LLM-assisted construction of AI concept hierarchies. 2024.
Lösungen: Prozessmanagement






